Algospeak as Register-Potential: Multimodal Communication Manipulation in Response to Algorithmic Content Moderation on TikTok
Author: Erynn Young, University of Amsterdam
Abstract:
In this article, I report the results of a data collection study on TikTok algospeak (e.g. seggs for ‘sex’), multimodal communication manipulation users deploy to evade algorithmic scrutiny and navigate platform visibility. Users’ algospeak communications were observed to qualify the manipulation mechanisms at work, with specific attention paid to multimodality – how users strategically exploit the platform’s architecture, technical capabilities, and interactive conventions across the written/textual, spoken/audio, and visual/video communicative modalities. Based on these data, I propose a preliminary taxonomy of algospeak strategies for communication manipulation. I conceptualize these algospeak strategies as comprising a kind of emergent register of computer-mediated communication (CMC), or register-potential, deployed in response to shifting platform-specific capabilities, constraints, and users’ perceptions of content moderation threats. In my contribution to growing algospeak literature, I foreground CMC registers as a conceptual apparatus by which multimodal algospeak can be understood. I highlight algospeak’s multimodality to situate it within CMC register discourses, considering TikTok’s technological architecture and how it enables a fluidly multimodal register like algospeak to emerge.
Keywords: algospeak, TikTok, content moderation, multimodality, language variation
Content warning: sexual content, suicide, death, pedophilia
1. Introduction
On the platform TikTok, content guidelines and their enforcement through algorithmic content moderation compel users to communicate appropriately or risk censorship (Blunt et al., 2020; Knight, 2022; Levine, 2022; Lorenz, 2022). In response, users manipulate their communication – called algospeak for algorithm speak – to avoid this algorithmic scrutiny (Calhoun & Fawcett, 2023; Steen et al., 2023); users self-censor to try and game TikTok’s terms of use, changing words such as ‘kill’ or ‘die’ to unalive, or ‘sex’ to seggystime. Algospeak is becoming increasingly popular, with recent surveys showing nearly 72% of TikTok users aged 18-24 encounter algospeak and 41% deploy it (“Survey”, 2022). In this data collection study, I observed users’ algospeak communications to qualify the manipulation mechanisms at work, with specific attention paid to their multimodal creativity – how users strategically exploit the platform’s architecture, technical capabilities, and interactive conventions across the written/textual, spoken/audio, and visual/video communicative modalities. These manipulation mechanisms were analyzed and used to inform a bottom-up strategy categorization schema. The emergent taxonomy of algospeak strategies as a conceptual tool is this study’s contribution.
Shifting away from a quantitative, lexicon-constructing approach, I position algospeak as computer-mediated communication (CMC)[1] register-potential, by which users can achieve algorithmically avoidant communication. On TikTok, successful (i.e. non-moderated) communication is not contingent on the adoption of specific lexical forms but on the fluid application of a range of communicative possibilities. This theoretical positioning and emergent algospeak taxonomy build upon developing algospeak research; Steen et al. (2023) and Calhoun and Fawcett (2023) motivate users’ algospeak use in response to the inequitable mobilization of content moderation against certain users/topics. Calhoun and Fawcett (2023) also investigate many of the manipulation strategies constituting algospeak, framing it as self-censoring, informal though systematic language play. In my contribution to growing algospeak literature, I center CMC registers as a conceptual apparatus by which algospeak can be understood. Moreover, I specifically highlight algospeak’s multimodality, considering TikTok’s technological architecture and how it enables a fluidly multimodal register-potential like algospeak to emerge. This further contributes to CMC discourse as the boundaries between register/modalities are increasingly blurred.
2. Computer-mediated communication (CMC)
Early research into computer-mediated communication (CMC) sought to understand how communication in the burgeoning digital frontier compared to (e.g. Crystal, 2006) or complemented (e.g. Baron, 2003) non-CMC communication. These early conceptualizations of CMC situated it along a register axis, with spoken and written registers as opposite poles, and qualified its communicative practices as more or less speech or writing-like (Baron, 2003). Registers could here be understood as the spoken or written communicative modalities in conjunction with the respective conventions, functions, and contexts that were considered to accompany these modalities. CMC was, according to Crystal (2006), a broad amalgamation of written and spoken communicative qualities, practices, and behaviors that skewed towards a written register. CMC integrated many properties of speech, including interactive synchronicity across CMC types (e.g. IM, chat rooms) and a lack of message permanence – depending on the medium. Among other adaptations of written/textual communicative phenomena to digitally/textually mediated environments, CMC users also relied/rely on approximated prosodic properties of speech through, for instance, manipulated punctuation and/or spelling (e.g. aLtErNaTiNg CaPs to indicate a mocking tone).
Unlike speech, the interactive synchronicity of CMC did not eliminate the delays between message production and reception (Crystal, 2006). CMC’s speech approximations were just that: approximations mediated textually; they were not the same as speech. The production of digital (text) messages required premeditation, followed by message production (i.e. typing), accelerating and condensing but not totally bypassing the processes of message production required when writing. Moreover, while the boundaries of message permanence were more fluid online, digital interactions were not universally transient. Crystal (2006) recognized the variable, creative, and innovative assortment of speech and writing features that make up CMC; nevertheless, such assessments of (early) CMC likened it to a digitally mediated writing-adjacent register – though stylistically diverse and rich in interactive resources (2006). Below is a representation of the conceptualized register/modality axis, with CMC closer to written registers.
2.1 CMC: Register or registers?
CMC platforms’ architectures and technological capabilities and constraints – like character limitations – provided insight into CMC features such as abbreviation use, form shortening, and casual interactive styles (Baron, 2003; Crystal, 2006; Tagliamonte & Denis, 2008; Tagliamonte, 2016; Thurlow, 2003). CMC challenged assumptions, expectations, and conventions about the boundaries of spoken and written communication, undergirded by CMC users’ adaptations of these registers to meet novel interaction needs (Baron, 2003). These characteristics of CMC were initially treated deterministically, thought of as comprising a distinct internet or “netspeak” register (Crystal, 2006; Baron, 1984), with its own interactive context and style. This conceptualization overlooked the diversity of early digital platforms and sites, collapsing the scope of communication variability to constitute a singular CMC register. As CMC platforms and technologies proliferated and advanced, so did CMC capabilities, constraints, functionalities, features, styles, forms, and users. This diversification of CMC was accompanied by the clustering of certain situational factors according to interaction and/or technology type, which encouraged the clustering of certain communicative features and styles that CMC users found better served these situations (Baron, 2003; 2008; Tagliamonte, 2016).
Over time, CMC was better understood as comprised of numerous communicative registers, shaped by varying configurations of situational factors, from social to technical, across different platforms (Baron, 2003; Tagliamonte, 2016). Tagliamonte’s (2016) investigation of three CMC registers – email, texting (SMS), and instant messaging (IM) – sought to delimit these registers through comparative analyses of orthographic, grammatical, and lexical features. Below is a visualization of where these CMC registers could fall along the register/modality axis.
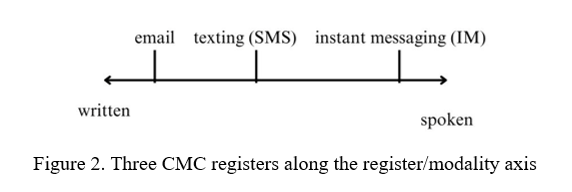
Tagliamonte (2016) found the boundaries of each register are not rigidly fixed but are driven by social conventionalization, context narrowing, and interactivity among users, taking into consideration interactive goals, platform capabilities and constraints. Users can “fluidly navigat[e] a complex range of new written registers… using conventions that are particular to each one” (2016, p.28), highlighting user sensitivity to register. While some CMC artifacts (e.g. shortened forms, abbreviations) are more or less frequent within certain registers (e.g. more frequent within IM, SMS), this should not be treated deterministically. The frequencies and types of CMC features shift across contexts and platforms but also across time and within users’ communications (2016). This less rigid view of CMC registers proves useful as a framework for algospeak research because it enables analyses of emergent CMC phenomena that foreground situational, interactive, technological, and multimodal potentialities in a way that maintains a theoretically informative referential point to digital communication and linguistic scholarship by utilizing the concept of archetypal registers/modalities while continuing to challenge technological and register determinism that influenced much early CMC analysis.
3. TikTok: architecture, capabilities, and constraints
On TikTok, users use audio, visual, and textual communication modalities to express themselves, interact, and as a whole, generate content. The main vehicle for content distribution is the For You feed (FYF), a page of novel, viral, and seemingly endless content determined by algorithmic recommendation systems that service users by monitoring their behavior on the app in order to curate content to their tastes and possible interests (through algorithmic, predictive patterning). FYFs function as both a distributive channel – content distributed via FYFs has greater visibility and higher likelihoods of achieving virality (Lorenz, 2022) – and a means of filtration, since content moderation processes determine whether content is eligible for FYFs through sociocultural politics of desirability, acceptability, and mass appeal (Gillespie, 2022).
Users must comply with TikTok’s terms of use called community guidelines. These guidelines are intended to foster a safe interactive space, simultaneously “enabling expression and preventing harm” (TikTok, 2023). They prohibit the representations of many topics, including sexual activities, harassment, and violent extremism. Certain content categories and topics are flagged as inappropriate; yet there is no substantive list of banned words, leaving users’ understandings of how TikTok mobilizes its guidelines when moderating content underinformed. TikTok also stresses that nuanced content (e.g. sensitive content presented for educational purposes) is exempt from strict moderation enforcement to enable “individual expression on topics of social importance” (2023a); however, the sensitive nature of such content may affect its eligibility for FYFs, so content visibility may be reduced. Generally, users are prohibited from sharing content that violates these guidelines. If a user violates a guideline, the content is removed; repeat violations can lead to permanent banning. To enforce these guidelines, TikTok employs “a mix of technology and human moderation” (TikTok, 2023): first using algorithms that evaluate content for predictable triggers, followed by human content moderators who perform additional content reviews, while also providing users with the ability to report content themselves (Gorwa et al., 2020). These moderating practices are applied to all content on the app (i.e. audio, textual [captions, comments, subtitles, etc.], visual).
This foregrounding of content moderation on TikTok heightens metalinguistic awareness among users since communication is the primary means of content creation and engagement; algospeak communication manipulation is simultaneously a reactive speech-chilling to avoid moderation (Knight, 2022; Ong, 2021; Penney, 2017; Roberts, 2020), and a proactive, defensive practice. As noted above, algospeak helps users beyond simple algorithmic evasion: through maintaining platform visibility/access and increasing audience reach through FYF eligibility and distribution. Without explicitly forbidden words and little operational transparency regarding TikTok’s content evaluation practices, users must develop functional definitions of algorithmic content moderation – algorithmic imaginaries or folk theories (Bucher, 2017; DeVito et al., 2021; Karizat et al., 2021) – and use these definitions to inform their communication practices. Algospeak is the mobilization of users’ perceptions of at-risk content, reflecting algorithmic folk theories and demonstrating how users use manipulated communication as one resource for facilitating interactions and maintaining visibility amid threats of content moderation and deplatforming (Calhoun & Fawcett, 2023; Steen et al., 2023).
4. Data and methods
4.1 Data collection procedure
To identify and categorize algospeak strategies on TikTok, I collected data over multiple periods. The initial data collection period lasted 17 months, from July 2022 through November 2023. Two supplemental periods of data collection occurred in late 2024 and late 2025. These data were collected through multiple methods. One method involved FYF observation until algospeak tokens were encountered, triggering further observation through snowballing; I explicitly queried algospeak tokens encountered during snowballing using TikTok’s search function. Through these queries, I encountered additional algospeak tokens; for example, a query of seggs (‘sex’) resulted in the discovery of one user’s account – a self-identified seggs education specialist – whose videos revealed other algospeak tokens pertaining to sexual content. I also conducted similar queries of algospeak tokens that have garnered notoriety (e.g. metalinguistic discourse across social media platforms, journalistic articles). These queries revealed users’ variably multimodal algospeak deployments as well as slight orthographic variations (e.g. segs, seggs, segggs). As TikTok’s search function scrubs all multimodal content to generate search results, I did not prioritize hashtags as an explicit method of query/data collection since hashtag data is captured through queries.
I collected algospeak data using a single device and pre-existing account without any content restrictions, nor any explicit account holder demographic information besides age. The account was created in 2021 and was not used to generate content. Prior to data collection, the account was used for casual content viewing; most of the content engaged or interacted with (i.e. ‘liking’ a video) contained social/cultural/political/ideological discourses, commentaries, and dialogues. This involves content in which creators engage with oppositional, controversial, trendy and/or politicized topics to engage in critical discussions. This is facilitated through TikTok’s stitching and duetting functions, by which users incorporate intertextual/referential content from other users on the platform, engaging in asynchronous, public dialogues. Such content can often feature algospeak as many of the topics discussed involve themes possibly at risk for moderation.
4.2 Data identification and categorization
In addition, I referenced TikTok’s community guidelines, users’ metalinguistic commentary, and existing familiarity and contact with algospeak (e.g. Levine, 2022; Lorenz, 2022) to facilitate the identification of algospeak tokens within observed TikTok content. Familiarity with TikTok’s community guidelines as well as with ongoing metalinguistic/pragmatic discourse about algospeak and TikTok content moderation is crucial for algospeak research, as this contextual and background knowledge enable data observers and analysts like myself to anticipate algospeak communication while engaging with content – conversational topics that approach or directly treat those prohibited or limited by the community guidelines often contain algospeak – and to perceive the traces of unfamiliar or novel algospeak strategies through their tokens as proxies.
Unique algospeak tokens were recorded, glossed (i.e. translated to pre-manipulated forms), and annotated (i.e. modality(s) used, content theme, and algospeak mechanism(s) engaged) when they were encountered within TikTok content. Following data collection, I labeled the observed mechanisms of algospeak manipulation inductively. I deciphered the algospeak tokens through intuitive and contextual reverse-engineering of the manipulation mechanism(s) at play; this is the same reconstructive process users engage in to decipher algospeak. For example, when the algospeak token seggs (meaning ‘sex’) is encountered, users/audiences might either hear the creator or text-to-speech utter the token seggs (/segs/), read or utter it themselves. The uttering of seggs highlights its phonological similarity to the censorable token sex (/seks/), and in conjunction with other contextual factors including content topic/theme and surrounding utterance, the token can be accepted as an algospeak alternative to ‘sex.’ From this, it is also made evident the primary mechanism of manipulation being deployed is one based on the manipulation of (some) phonological qualities. I applied this process of token-strategy categorization to the dataset. I also grouped recurrent instances of similar manipulations mechanisms together under broad categories (e.g. types of phonological manipulation categorized under Phonological Manipulation).
4.3 Dataset
A total of 290 algospeak tokens were recorded. The data were considered sufficient after 2-3 months during which no new strategies – although countless new tokens and variations – were encountered. In total, I identified 21 strategy categories and 46 strategies. For the scope of this study, I restricted the collected data to algospeak situated within English language content. Importantly, this collection of algospeak strategies is not exhaustive; given the fluid and creative possibilities of algospeak variation, the volume of data on TikTok, and the critical question of whether strategies/tokens not encountered do not exist or are ineffective (i.e. censored), it was not possible to observe all strategies of communication manipulation. I also encountered iterative variations of algospeak tokens (e.g. seggs, segggs) during data collection. Since the focus of this data collection study is to qualify algospeak’s manipulation mechanisms and develop a preliminary taxonomy, such tokens were not systematically recorded beyond considerations of strategy layering and/or iteration. These tokens functionally belong to the strategy categories of their less iterative counterparts (e.g. seggs). These token variations are considered as manifestations of users’ varying algorithmic literacies/imaginaries and/or individual censorship threat risk assessments.
Since the data were collected using a single device with an existing account, TikTok’s recommendation systems have, true to their form, curated the content on the selected FYF. This means the dataset is limited; this limitation also bears upon the types of algospeak tokens encountered and recorded. However, the highly intertextual/dialogic nature of content on the selected FYF (via TikTok’s stitch function) expands content visibility from any single device and account since content featured on one’s FYF can include stitches with (minimally) one additional video/comment. During data collection, I observed algospeak content from both the primary content on the FYF and from secondary, stitched content not otherwise visible via the FYF. Given my aim to qualify algospeak’s mechanisms for manipulation, regular access to algospeak in action was preferred over creating a new account and risking uncertain or incidentally limited access to algospeak during the delimited time periods for data collection.
5. Taxonomy of algospeak strategies
The emergent taxonomy is shown below in table 1 with example tokens from the dataset. Few strategies, if any, are restricted to one modality, owing to TikTok’s multimodal resources, encouraged fluidity across modalities, and users’ deployment of cross-modality convergence and/or divergence depending on their interactive goals and their individual abilities and constraints. Cross-modality convergence refers to users’ deployment of an algospeak strategy (or several) consistently across modalities. For example, a user writes seggs within closed captioning and utters seggs (/segs/). Cross-modality divergence refers to users’ inconsistent deployment of algospeak strategies across modalities. For example, a user writes seggs but utters ‘sex’ (/seks/). Users fluidly communicate in and out of algospeak, using a manipulation mechanism from one modality to inform subsequent (often simultaneous) manipulations in other modalities. Nevertheless, considerations of dominant modalities engaged for the different algospeak strategies helps to conceptually distill the aspects of language that are being consciously manipulated when users use algospeak. The taxonomy is organized according to the dominant modality(s) a given strategy engages. A selection of these strategies is detailed further below.
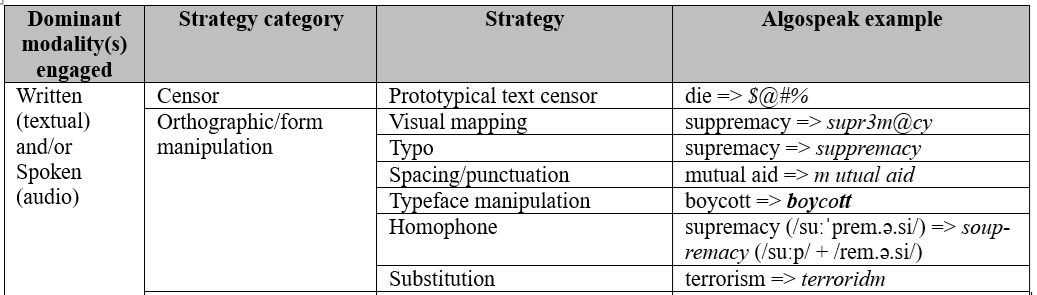
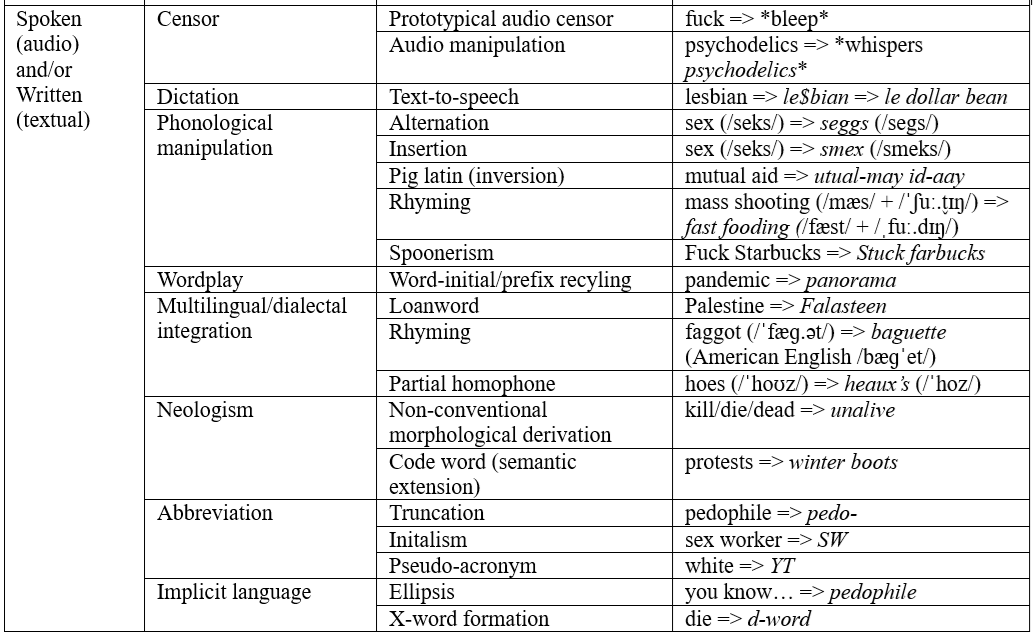
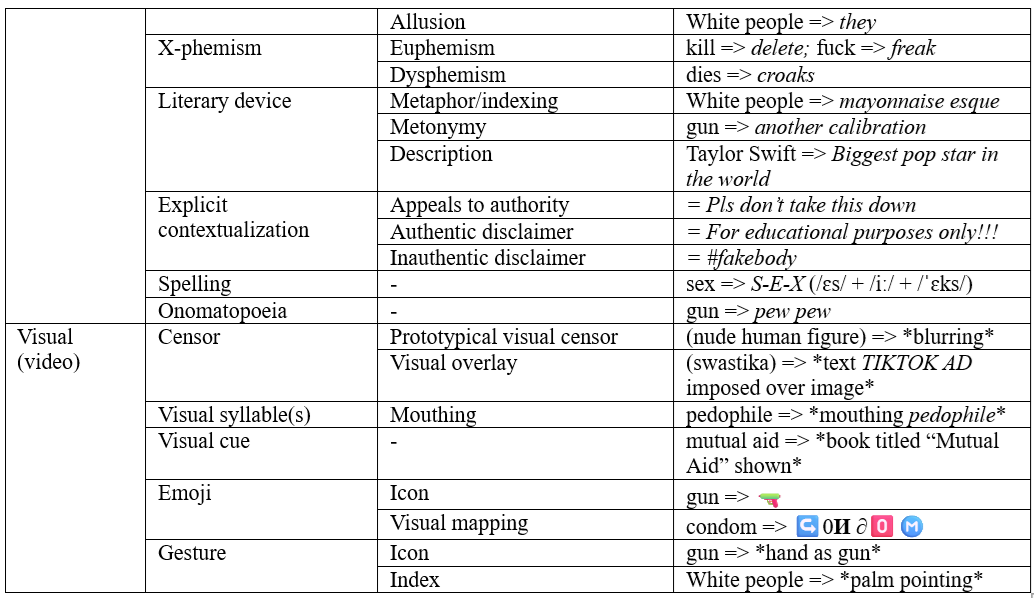
Table 1. Taxonomy of algospeak strategies
5.1 Dominant modality: written/textual
5.1.1 Orthographic/form manipulation
Strategies of orthographic/form manipulation include visual mapping, which substitutes alphabetic characters with visually resemblant ASCII characters. Visual mapping is a familiar strategy for digital word filter evasion. Visual mapping, also known as l33tspeak, hackers’ language (Danet, 2001; Sherblom-Woodward, 2002) or rebus writing (Crystal, 2011; Deumert, 2014), uses ASCII characters to manipulate filter legibility of tokens while maintaining visual continuity for audience intelligibility. For example, in supr3m@cy, 3 and @ replace E- and A- respectively; the ASCII characters visually map onto the characters they substitute, facilitating legibility for audiences. Typos like suppremacy avoid algorithmic detection by duplicating letters within a word, interrupting a linguistically meaningful token. Similarly, spacing/punctuation manipulation (e.g. m utual aid) and substitution (e.g. terroridm for ‘terrorism’) interrupt linguistically meaningful tokens. Another strategy, homophones, uses homophone(s) of part of or all of a potentially violative word to neutralize it at the token level; the algospeak token soup-remacy (/suːp/ + /rem.ə.si/) retains the phonological integrity of ‘supremacy’ (/suːˈprem.ə.si/) but does not retain its potentially violative orthographic integrity.
5.2 Dominant modalities: spoken/audio and/or written/textual
5.2.1 Phonological manipulation
Phonological manipulation alters audio linguistic content to avoid detection. Alternation occurs when users replace part of a word with alternative phonemes[2]; ‘sex’ becomes seggs. With seggs, the consonant -X is replaced with consonant cluster -GGS, altering the pronunciation slightly from /seks/ to /segs/. The consonants /k/ and /g/ share articulatory qualities including place of articulation; phonological similarities facilitate audience intelligibility so they can retrieve the intended meaning. Insertion involves users’ insertion of any letter/phoneme or cluster of letters/phonemes, as in smex for ‘sex.’ Rhyming retains the pronunciation of a word’s final syllables while swapping phonemes or syllables at the beginning of the word. For example, mass shooting (/mæs/ + /ˈʃuː.t̬ɪŋ/) is transformed to fast fooding (/fæst/ + /ˌfuː.dɪŋ/). Pig latin (inversion), where for example ‘mutual aid’ becomes utual-may id-aay, can be redeployed for algospeak purposes. Another strategy involves generating spoonerisms: users swap the initial phonemes or syllables of at least two words: ‘fuck Starbucks’ becomes stuck farbucks.
5.2.2 Neologism
Unalive is formed through non-conventionalized morphological derivation whereby users apply existing morphological conventions to create new words, or neologisms. For unalive, meaning ‘kill,’ ‘die,’ ‘dead,’ or ‘death,’ the negating prefix UN- is combined with the stative adjective ALIVE to create a token that negates the state of being alive. Unalive is also syntactically fluid; it can function as a noun, adjective, and verb. When substituting ‘kill,’ unalive removes causal agency, which may provide additional protection from content moderation by removing reference to explicitly violent agent(s). Derivations can be further modified through additional morpheme-affixing: self-unalive, meaning ‘commit suicide.’ These derivations are semantically continuous with the words they replace, facilitating audience comprehension. In this category, I have also classified code words, whereby users semantically extend existing words to new meanings; for example, the phrase winter boots is semantically extended to mean ‘protests.’
5.2.3 Literary device
To generate algospeak metaphors, users identify salient characteristics of their target concepts, select alternative concepts that share one/some of these characteristics, and subsequently map their language across these domains. These metaphors retain some semantic continuity between start and end concepts, which facilitates message intelligibility. For example, palm-colored ppl, mayonnaise esque, and children of chalk are metaphors – taken from AAE – for ‘White people.’ Users identify the quality of being white as salient to ‘White people’; next, they identify alternative concepts that share this quality. They bridge these concepts together through metaphorical substitution. Users also use metonymy, where they refer to a possibly censored word by one of its attributes or components; one user replaces ‘gun’ with another calibration. Description falls under this category as well. Users replace at-risk words or topics with a description of the concept in question: “Taylor Swift” is instead Biggest pop star in the world.
5.3 Dominant modality: visual/video
5.3.1 Emoji
Users employ emojis to convey meaning by mapping words to their visually iconic counterparts; for example, 🔫 for ‘gun’. Users also layer emoji use with metaphorical manipulations, like turning ‘cocaine’ to snow, and then further obfuscating through emoji: ❄️. One user uses the mixed text-emoji sequence ↪️0ᴎd🅾️Ⓜ️ for ‘condom,’ where alphabetic characters are mapped onto their alphabetic emoji approximations. Another user blends emojis and word fragments with ⚪️🍜remacy to substitute the phrase ‘White supremacy,’ retrieving from the 🍜 emoji its homophonic qualities: soup (/suːp/) for the first syllable of supremacy (/suːˈprem.ə.si/).
5.3.2 Gesture
Gestures can be iconic (e.g. hand gesturing a gun) or indexical, like palm pointing to indicate ‘White people.’ Palm pointing, also derived from AAE, evokes the same indexical relationship mentioned earlier between the metaphor palm-colored and ‘White people’. Gestures like palm pointing evade both (textual) word filters and audio content moderation. Moreover, since palm pointing is indexical, there is an added layer of message encoding that makes flagging through automated content moderation systems more difficult.
6. Discussion
TikTok’s multimodal architecture, content moderation practices, and users’ goals of agentive and intelligible communication intersect to cultivate an interactive environment that is incredibly demanding of its users, requiring heightened metalinguistic sensitivity. To meet these demands, users manipulate their communication, incorporating numerous variation tactics in multimodally layered ways, creating a distinctively complex and fluid semiotic environment in which tokens are continually generated. Users exploit communication modalities within their uses of algospeak to manage potentially contradictory interactive goals like message intelligibility and covertness. Some users practice cross-modality convergence by self-censoring across all modalities (textual, audio, visual). Some practice cross-modality divergence by using manipulated and non-manipulated tokens across modalities; for example, some utter the word ‘white’ while pointing to their palms, and others add text overlays/stickers that contain violative words like ‘pedophile’ while mouthing it. In addition to intelligibility management, cross-modality convergence and/or divergence are driven by users’ varying perceptions of content moderation threats, dependent upon how extensive they believe TikTok’s content moderation capabilities are (Bucher, 2017; DeVito et al., 2021; Ong, 2021; Steen et al., 2023).
Algospeak strategies can also be blended or layered. 🌽, substituting ‘porn,’ relies first on the rhyming manipulation of ‘porn’ to corn (also used as algospeak); corn is then mapped onto its iconic emoji. Additionally, slight orthographic variations of algospeak manipulations (e.g. iterative spelling variations of seggs like segggs, seggggs, seggggggs, etc.) exemplify an additional strategic layer to algospeak communication, whereby users conduct some initial process of manipulation – in this example, the alternation of phonological components – transcribe this change through text and iterate it. The more users are exposed to and apply these strategies, the sharper users’ algospeak sense-making skills become, and the lower the necessity is for tokens to be conventionalized within users’ digital lexicons for effective algospeak communication. In fact, the more entrenched a particular algospeak token becomes in users’ lexicons (e.g. unalive is ubiquitous and notorious [Levine, 2022]), the more possible it becomes that TikTok’s content moderation systems will learn accordingly, integrating locally conventionalized tokens into algorithmic filters. My conceptualization of algospeak as a perpetually ongoing process and not a resultant lexicon shifts focus away from the exoticization of netspeak neologisms and questions of token conventionalization, stability, and longevity within lexicons (Behera, 2013; Crystal, 2011). Instead, I propose that algospeak is a valuable and amorphous interactive resource for communication manipulation within and across modalities, capable of being blended, layered, or iterated, generating even more communicative possibilities.
6.1 The algospeak register
Is algospeak then a kind of CMC register, situationally specific and functionally relegated to the boundaries of TikTok? I consider the distinctive characteristics of algospeak. Baron (2003) identifies four variables that shape CMC and provides useful analytical means of assessing distinct types of CMC: message function, device constraints, particular linguistic features, and user populations. Beginning with message function, algospeak balances covert communication that evades algorithmic scrutiny/censorship with intelligibility maintenance among audiences. Users’ functional definitions of risky content vary substantially and these bear upon the types, quantity, and quality of algospeak they use. Nevertheless, users cannot manipulate beyond the scope of what is retrievable for audiences in terms of meaning. So, strategies involve manipulative mechanisms that users hope can be disambiguated by audiences, like visual mapping or iconic emojis. Metaphors and non-conventionalized morphological derivations can maintain semantic continuity to target concepts so users can retrieve the intended meanings. As the manipulative mechanisms become more complex, algospeak users must increasingly integrate cues, context, or even diverge their communication subversion across modalities to facilitate comprehension.
Device constraints as originally conceptualized by Baron (2003) are not as influential in determining register boundaries on TikTok since the platform is accessible through smartphones and desktop computers; I instead consider its platform constraints (and capabilities) as driving algospeak necessity and use. TikTok enables multimodal interactivity; users primarily communicate through written/textual, spoken/audio, and visual/video modalities. Many of TikTok’s technical features, including multimodal comment reaction capabilities and video closed captioning, encourage users’ fluid movements within and across modalities as they engage with content and users. Comments are limited to 150 characters; however, users can submit multiple comments in a thread, mitigating some of this constraint. Full keyboard access (on phones and computers) can facilitate the use of non-alphabetic characters, symbols, and emojis. Videos can last up to 10 minutes which, coupled with editing features like jump cuts and playback speed manipulation, can provide ample time to communicate; this can allot time for more time-demanding algospeak strategies, such as description. Editing features can enable varying degrees of strategy layering through cross-modality convergence and/or divergence (e.g. adding visual text that translates algospeak). Finally, TikTok’s community guidelines constitute interactive constraints since they delimit – albeit opaquely – the boundaries of permissible content.
TikTok’s user population is immense and global; the platform boasts nearly two billion users. Most users are young, between 18-24 years old (Ceci, 2024). Given this dominant age demographic, it is perhaps less surprising that a novel, fluid and adaptive communicative phenomenon like algospeak is emerging on the platform. Much sociolinguistic research into CMC finds that younger users tend to be more linguistically adaptive, innovative, and playful (Tagliamonte, 2016; Tagliamonte & Denis, 2008; Thurlow, 2003). I also consider TikTok’s content distribution and its role in facilitating algospeak. Content is fed to users through their FYFs, which algorithmically curate content based on preferences indicated actively – through engagement behaviors like liking and commenting – and passively – through behaviors like content scrolling. TikTok’s content algorithms cultivate niches of like users by distributing similar content to those with similar interests. These niche user communities are fragile and ephemeral owing to the transient nature of trends, user interests, platform traffic, and the volume of content on TikTok. Nevertheless, curated communities can share ideologies, experiences, and access to cultural artifacts that facilitate intercommunal deployment/comprehension of algospeak.
Lastly, particular linguistic features are borne out of algospeak. Some strategies result in tokens that can be considered original or distinctive (e.g. le dollar bean). Strategies like code words instigate semantic shifts and/or imbue words with new, locally salient meanings: accounting is widely understood to also mean ‘sex work.’ Multilingual/dialectal borrowings exploit the situated nature of risky communication; the token Falasteen for ‘Palestine’ is romanized from Arabic. This romanized token, differing from the English spelling, form, and pronunciation, is not a communicative transgression in English language contexts. Algospeak also draws upon numerous historical antecedents for language manipulation, on and offline. L33tspeak is revived through algospeak via visual mapping. Phonological insertion and alternation, tried and true strategies for covert communication among stigmatized communities of gay speakers in Syria (Klimiuk, 2019), are adapted with digital platform algorithmic evasion as an expansive function.
According to these criteria for CMC register differentiation (Baron, 2003), algospeak constitutes a distinctive register of CMC. However, there is great deal of overlap between the algospeak register and both preceding and concurrent registers of digital and/or subversive communication from which it borrows many of its distinctive qualities. As remarked by Tagliamonte (2016), platform architectures are continually evolving and as they introduce greater and more expansive capabilities – particularly in terms of user interactivity/sociality – conceptualizing distinct CMC registers becomes less feasible. As digital, interactive multimodality is increasingly conventionalized through platforms like TikTok, earlier methods of distinguishing registers through modality comparisons are less useful. I propose algospeak clearly contributes to challenges of these conceptualizations of distinct CMC registers. It is fluidly multimodal in its application, integrating attributes and communicative possibilities of written/textual, spoken/audio, and visual/video modalities. Algospeak’s deployment is also selective and conservative; algospeak manipulation predominantly targets words that are at risk for moderation, leaving the rest of users’ communication unmanipulated. In other words, certain words and phrases are precluded from algospeak due to their potential risk of triggering algorithmic scrutiny; these require algospeak manipulation. Additionally, algospeak strategies draw upon features from existing CMC registers – like elisions and initialisms, found frequently within SMS and IM registers (Tagliamonte, 2016) – and beyond – like censorship mechanisms from television, radio, and observed communication practices of certain marginalized communities.
Algospeak is a convergence of many styles, CMC registers, languages and dialects, pulling from any and each when useful in evading localized algorithmic content moderation. Users move in and out of algospeak, despite remaining within a relatively continuous interactive environment, with its interactive constraints withstanding. I propose that algospeak is better conceptualized as an amorphous, constantly shifting clustering of communication potentialities – as register-potential – spanning communication modalities, excluding words that are deemed ineligible due to their heightened risk for moderation. Algospeak as register-potential is visually (statically) represented below in figure 3; figure 3 also expands more simplified representations of CMC registers that span only a written-spoken modality axis to include the visual modality.
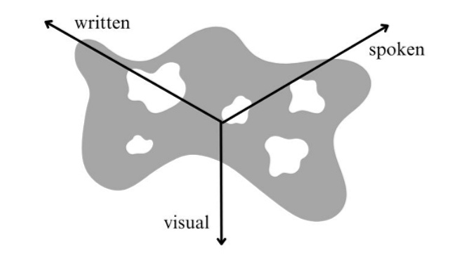
Figure 3. Algospeak register-potential superimposed over a register/modality spectrum
Algospeak as CMC register-potential is even less stable than its digital progenitors. It exists as a user-generated response to persistent and pervasive communication surveillance and moderation. This means it must remain adaptive not only to advances and changes to technological capabilities and constraints, but to content moderation systems that specifically target undesirable content. Thus, communication that is viable as algospeak – represented by the grey shaded area in figure 3 – must remain adaptive and never fixed. As TikTok’s content moderation practices develop, the shape or nature of algospeak and its constitutive strategies must necessarily develop in tandem; otherwise, algospeak risks being moderated out of existence, leaving users with less communicative and expressive agency and opportunities.
7. Conclusion
In their communication practices, TikTok users must constantly balance communicative efficiency with the evasion of algorithmic content moderation; algospeak as amorphous register-potential, comprised of multimodal communicative possibilities is one tool. While the investigated algospeak strategies are neither new nor characteristic of digital communication specifically (Barton & Lee, 2013), their creative, layered, and varied applications across written/textual, spoken/audio, and visual/video modalities show that users exploit a range of diverse communication manipulation strategies to serve a novel, localized function: evading content moderation and managing sociality on TikTok.
It is important to note some limitations of this data collection study. My proposed taxonomy is not exhaustive and will expand as users integrate more strategies for algospeak. Investigating algospeak in non-English languages will present other strategies for manipulation (Hosny & Nasef, 2025) and provide insight into possible translingual strategies for subversive communication. The dataset does not permit conclusions to be made about motivations for algospeak use beyond algorithmic evasion; speculations in this study about user creativity and playfulness are derived from algospeak that invokes manipulation mechanisms (e.g. homophones) linked to observations of linguistic play online (e.g. Danet, 2001). Future research should continue to investigate user motivations (e.g. ideological, accessibility) for algospeak strategy selection as well as its deployment in resistance to differentially moderated content resulting from racist/sexist/ableist/classist algorithmic and broader sociocultural normative positioning (e.g. Calhoun & Fawcett, 2023; Karizat et al., 2021). The indexical capabilities of algospeak (e.g. Knight, 2022) should also be explored, shedding light on algospeak as a performative sociolinguistic resource (e.g. identity) and as a metalinguistic resource (e.g. signaling users’ identities/positionalities as mediated through TikTok).
Algospeak is the result of constant algorithmic surveillance and moderation; it demonstrates how users negotiate communicative agency in response to algorithmic scrutiny, keeping communication possible by exploiting users’ communication manipulation (and disambiguation) capabilities in ways not yet effectively anticipated by algorithms. This highlights some limitations of current content moderation practices on TikTok; users demonstrate their abilities to manipulate communication beyond the scope of algorithmic content moderation (Gorwa et al., 2020; Roberts, 2020). By applying communication manipulation strategies fluidly, generating novel algospeak tokens with each application and divesting away from token entrenchment within their digital lexicons, users jointly cohere a CMC register(-potential) without discrete boundaries that enables them to outpace predictive algorithms, making communication moderation as a proxy for content moderation not fully enforceable. As algorithmic content moderation on digital platforms improves – through, for example, more substantive employment human content moderators to decipher algospeak and aid moderation (“Survey”, 2022) – users will need to further diversify their manipulation strategies, exploit their skills for creative meaning-making and continue to reshape algospeak potentialities.
Data availability statement:
The corresponding dataset for this study is available upon request from the author.
References:
Androutsopoulos, J. (2021). Polymedia in interaction. Pragmatics and Society, 12(5), 707-724. https://doi.org/qnb8.
Baron, N.S. (2008). Always On: Language in an Online and Mobile World. Oxford University Press.
----- (2003). Language of the Internet. In Farghali, A. (Ed.), The Stanford Handbook for Language Engineers, Stanford: CSLI Publications, 59-127. https://doi.org/p52g.
----- (1984). Computer mediated communication as a force in language change. Visible Language XVIII, 2, 118-141.
Barton, D. & Lee, C. (2013). Language Online: Investigating Digital Texts and Practices. Routledge.
Behera, B. (2013). The Burgeoning Usage of Neologisms in Contemporary English. IOSR Journal of Humanities and Social Sciences, 18(3), 25-35. https://doi.org/p52f.
Blunt, D., Wolf, A., Coombes, E., & Mullin, S. (2020). “Posting Into the Void: Studying the impact of shadowbanning on sex workers and activists.” Hacking//Hustling, bit.ly/3Vo2gTV.
Bucher, T. (2017). The algorithmic imaginary: Exploring the ordinary affects of Facebook algorithms. Information, Communication & Society, 20(1), 30-44. https://doi.org/gddv8f.
Calhoun, K. & Fawcett, A. (2023). “They Edited Out Her Nip Nops”: Linguistic Innovation as Textual Censorship Avoidance on TikTok. Language@Internet, 21, article 1. https://doi.org/p52c.
Ceci, L. (2024). Distribution of TikTok users worldwide as of January 2024, by age and gender. Statista, bit.ly/3K7wKaw.
Crystal, D. (2011). Internet Linguistics. Routledge.
----- (2006). Language and the internet. Cambridge University Press.
Danet, B. (2001). Cyberpl@y: Communicating Online. Routledge.
Deumert, A. (2014). Sociolinguistics and Mobile Communication. Edinburgh University Press.
DeVito, M.A., Gergle, A., & Birnholtz, J. (2021). “Algorithms ruin everything”: #RIPTwitter, folk theories, and resistance to algorithmic change in social media. Proceedings of the 2017 Conference on Human Factors in Computing Systems, 3163-3174. https://doi.org/gnhcd3.
Gillespie, T. (2022). Do Not Recommend? Reduction as a Form of Content Moderation. Social Media + Society, 8(3). https://doi.org/p52b.
Gorwa, R., Binns, R., & Katzenbach, C. (2020). Algorithmic content moderation: Technical and political governance. Big Data & Society, 7(1). https://doi.org/ggsfrk.
Hosny, R. & Nasef, M.A. (2025). Lexical algorithmic resistance: Tactics of deceiving Arabic content moderation algorithms on Facebook. Big Data & Society, April-June(1-17). https://doi.org/qnb7.
Karizat, N., Delmonaco, D., Eslami, M., & Andalibli, N. (2021). Algorithmic Folk Theories and Identity: How TikTok Users Co-Produce Knowledge of Identity and Engage in Algorithmic Resistance. Proceedings of the ACM on Human-Computer Interaction, 5(2), 1-44. https://doi.org/g9hvqg.
Klimiuk, M. 2019. Geheime talen en woorden: het ‘gay Arabisch’ in Syrië [Secret languages and words: ‘gay Arabic’ in Syria]. Zemzem 2/2019, 71-79.
Knight, M.E. (2022). #SEGGSED: Sex, Safety, and Censorship on TikTok. [Master’s thesis, San Diego State University].
Levine, A.S. (2022, September 19). ‘From Camping To Cheese Pizza, “Algospeak” Is Taking Over Social Media.’ Forbes, bit.ly/3Vi9AAA.
Lorenz, T. (2022, April 8). ‘Internet “algospeak” is changing our language in real time, from “nip nops” to “le dollar bean.”’ The Washington Post, bit.ly/47JAnNy.
Ong, E. (2021). Online Repression and Self-Censorship: Evidence from Southeast Asia. Government and Opposition, 56(1), 141-162. https://doi.org/gnn9qd.
Penney, J.W. (2017). Internet surveillance, regulation, and chilling effects online: a comparative case study. Internet Policy Review, 6(2). https://doi.org/p5z9.
Roberts, M.E. (2020). Resilience to Online Censorship. Annual Review of Political Science, 23, 401-419. https://doi.org/ggvfqq.
Sherblom-Woodward, B. (2002). Hackers, Gamers and Lamers: The Use of l33t in the Computer Sub-Culture. [Master’s thesis, University of Swarthmore].
Steen, E., Yurechko, K., & Klug, D. (2023). You Can (Not) Say What You Want: Using Algospeak to Contest and Evade Algorithmic Content Moderation on TikTok. Social Media + Society, 9(3). https://doi.org/gt3tz2.
Survey: ‘Algospeak’ on the Rise in Attempt to Avoid Automated Content Moderation. (2022, September 8). TELUS Digital, bit.ly/41TO5K5.
Tagliamonte, S. (2016). So sick or so cool? The language of youth on the internet. Language in Society, 45, 1-32. https://doi.org/gdm7xv.
Tagliamonte, S. & Denis, D. (2008). Linguistic ruin? LOL! Instant messaging, teen language and linguistic change. American Speech, 83, 3-34. https://doi.org/fpmffn.
Thurlow, C. (2003). Generation txt? Exposing the sociolinguistics of young people’s text messaging. Discourse Analysis Online 1.
TikTok. (2023). Community Guidelines. TikTok. bit.ly/4nyrXgB.
[1] I use computer-mediated in the most expansive sense of computer/modern computing. Recent scholarship has pushed for a renaming of this discipline as digitally-mediated interaction (DMI) (Androutsopoulos, 2021).
[2] This is not a fixed modality boundary, as some users also write seggs and pronounce seggs (/segs/), while others write ‘sex’ and pronounce seggs (/segs/), and still others write seggs and pronounce sex (/seks/).