On the Nature of Crosslinguistic Variation: Insights from Anaphora
Authors:
Thomas McFadden, Stony Brook University
Sandhya Sundaresan, Stony Brook University
Hedde Zeijlstra, University of Goettingen
Abstract:
Do systematic interpretive contrasts across languages derive from the employment of universal grammatical building blocks, or do they stem from differing semantic specifications on simplex formatives that feed into (Neo-Gricean) pragmatic reasoning? Is evidence for grammatical features underlying a particular contrast in one language an argument for those features being universal and thus present in another language where such evidence is lacking? In this paper, we explore this complex of big-picture questions on the basis of so-called *ABA patterns, especially in the area of nominal pro-forms, i.e. the various types of anaphors and pronouns. To sharpen the issues, we compare two radically opposed perspectives, which we dub Rich Universal Base and Poor Universal Base. We show that either one could in principle account for the basic *ABA facts, leaving the door open for an unsatisfying debate on conceptual and aesthetic grounds. We thus explore ways in which the debate can be put back onto an empirical footing by identifying distinct predictions that the two approaches make for the behavior of surface forms that are ambiguous between anaphoric and pronominal reference. We then use these to develop concrete diagnostics and give a preliminary demonstration of how they might be applied in languages with the right cluster of properties to empirically resolve the debate.
Keywords: universals; cross-linguistic variation; *ABA; anaphors; pronouns; Neo-Gricean reasoning
1 Background
The goal of this paper is to explore how the nature of language variation can be explored through the empirical lens of cross-linguistic patterns of morphological syncretism for nominal pro-forms, i.e. the various types of anaphors and pronouns. We begin here by expounding on the tensions concerning the proper analysis of language universals and variation and detail how patterns of cross-linguistic syncretism can help adjudicate the choice between different approaches to this issue while crucially also anchoring the debate on a solid and objective empirical footing.
1.1 Language universals and variation
A fundamental question for linguistic theory revolves around the tension between what is universal and what varies across languages. Concretely, what are the fundamental building blocks of grammar, how are they organized and ordered relative to each other, how much of this is universal, and in what ways can languages vary in this respect?
We can identify two extreme positions, appropriating labels used in Wiltschko (2014). The Universal Base Hypothesis (UBH) propounds the idea (going back to Chomsky, 1965; Ross, 1970, a.o.) that “The deep structures of all languages are identical, up to the ordering of constituents immediately dominated by the same node” (Ross, 1970, 260). In other words, the ordering as well as the inventory of linguistic building blocks are cross-linguistically consistent. At the other extreme is the No Base Hypothesis (see e.g. Evans and Levison, 2009; Haspelmath, 2007) which postulates that universals are simply non-existent in the inventory and arrangement of building blocks. As such, languages can vary in arbitrary and potentially infinite ways in this area. But as Wiltschko (2014) discusses in detail, adjudicating the choice between what is language-universal and what is language-variant is far from straightforward. On the one hand, scopal effects with respect to adverb orderings, and the relative positioning of clause-peripheral morphemes show a surprisingly robust uniformity across languages (Cinque, 1999, a.o.). Similarly, the function and relative ordering of nominal categories cross-linguistically parallel those of clausal ones. Such observations support the idea that some linguistic categories and their arrangement are universal (see also Wiltschko, 2014, for discussion). At the same time, mismatches between categorial inventories and distributions across languages clearly exist. For example, languages differ in which tenses or cases they precisely distinguish or whether they have a clusivity distinction in the 1st-person pronouns. Indeed, it is arguably the case that languages can differ in whether a particular category is part of the grammar at all. For example, gender and honorificity play important grammatical roles in a number of languages, while in others they seem to be irrelevant for the grammar, though may still clearly matter at lexical and semantic/pragmatic levels. These observations point toward a language-specific, rather than a language-universal, categorial classification.
Within the framework of Minimalism (Chomsky, 2000, 2001, et seq.), the Strong Minimalist Thesis (SMT) provides a heuristic which can help adjudicate the balance between these extremes. The SMT is the idea that “The optimal situation would be that UG reduces to the simplest computational principles which operate in accord with conditions of computational efficiency.” (Chomsky and Berwick, 2016, 94). In other words, we should assume that Universal Grammar (UG) has an optimally economical universal base. The problem is that, short of an independent metric for what is “optimal” or “economic” or, even, what counts as a grammatical building block, the SMT doesn’t actually provide clear guidelines for resolving this issue. The question threatens to be an aesthetically subjective rather than a scientifically objective one. In this paper, we seek to sharpen these thorny questions of language universality vs. language variance empirically, via the lens of cross-linguistic patterns of form-meaning pairings involving nominal pro-forms. In particular, we will examine the implications of morphological patterns of syncretism across classes of anaphor and pronoun for two Minimalist-compatible, but nevertheless opposing, views of language variation which we will label the Rich Universal Base (RUB) and Poor Universal Base (PUB).
1.2 Defining RUB vs. PUB
The Rich Universal Base (RUB) is the strong hypothesis that the grammatical base is (predominantly) universal. In particular, the basic building blocks of syntactic structure, as well as their relative ordering, are universal even at fine levels of detail. This implies that, to the extent possible, any differences in surface forms or meanings across languages must stem from language-specific processes of displacement, realization and interpretation that apply to the universal base. Language universals, on the other hand, stem from the universal base peeking through.
In contrast, the Poor Universal Base (PUB) is the equally strong opposing hypothesis that nothing (or hardly anything) about the inventory and ordering of basic building blocks should be assumed to be universal. Categories and structures should only be assumed to exist in a language if there is clear evidence for them in that same language, not on the basis of evidence from other languages. This means that the building blocks of syntactic structure are not necessarily universal, and can vary considerably across languages. Under this approach, language universals should be modelled, to the extent possible, via external factors, e.g. principles of efficient computation, general-purpose cognitive processes or the effects of language acquisition and use.
1.3 Defining a grammatical building block
RUB and PUB are framed in terms of the extent to which grammatical building blocks are universal, and critically evaluating them will require us to be explicit about what these are. Specifically, we will define grammatical building blocks as features, and we will take these to be the primitive units of structure building. Such a definition is concrete enough to get the discussion off the ground while allowing us to deliberately set aside the questions of how grammatical features map onto structural projections (i.e. syntactic heads) and onto grammatical categories. Those questions are indubitably interesting and have spawned their own rich research agenda and debate, but they are ultimately separate from the main concerns of this paper. For instance, the cartographic enterprise (Rizzi, 1997; Cinque, 1999, et seq.) in its strongest version, as within the framework of Nanosyntax (Caha, 2009; Starke, 2009; Baunaz, Haegeman, de Clercq, and Lander, 2018) assumes a one-to-one mapping between features and heads. Cartographic approaches constitute a classic instantiation of RUB, advocating for a rich sequence of functional heads (or functional sequence/fseq) whose inventory and hierarchy is universal across languages. But it is important to keep in mind that such approaches are not the only ones compatible with a RUB-based mindset. For instance, the head-bundling approach of Pylkkänen (2002) and the more recent head-splitting idea of Martinovi´c (2015) explicitly reject a one-to-one mapping of grammatical features to functional heads, but this point is orthogonal to our concerns here. Even if individual heads contain multiple features, one can still posit that their inventory and arrangement is universal across languages and thereby adopt a RUB-compatible approach. Defining grammatical building blocks in terms of grammatical features (rather than syntactic heads) thus constitutes a deliberate choice on our part to set aside this rich debate and focus, instead, on the questions of which building-blocks are universal and which language-specific, and how any cross-linguistic variation in the inventory and hierarchy of such building-blocks must be captured.
1.4 Exploring RUB and PUB via *ABA patterns
In this article, we address the tension between RUB and PUB by comparing two approaches to cross-linguistic restrictions on patterns of syncretism. A great deal of attention has recently been devoted to the so-called *ABA constraint, which was characterized as follows:
“Morphological paradigms can be ordered so as to observe the *ABA restriction, i.e. such that only contiguous cells in a paradigm are syncretic. Syncretisms thus reveal a hierarchy in paradigms, which is in turn accounted for in terms of a hierarchy of underlying features. Consequently, syncretisms can be used as a tool for the diagnosis of feature structures.” (Caha and vanden Wyngaerd, 2017)
Foundational discussions of *ABA patterns are found in Caha (2009) on case and (Bobaljik, 2012) on suppletion for comparative and superlative forms of adjectives.
We can demonstrate the basic phenomenon nicely with a brief look at the case distinctions in Modern Greek exemplified in Table 1.[1] The language has paradigms with distinct forms for

nominative, accusative and genitive (ABC), ones that syncretize nominative and accusative to the exclusion of genitive (AAB), others that syncretize accusative and genitive to the exclusion of nominative (ABB), and still others that have a single form for all three cases (AAA). There are none, however, that have a syncretic form for nominative and genitive alongside a distinct form for accusative (ABA). Caha (2009) argues that this is part of a broader, cross-linguistically consistent pattern implicating a universal hierarchy of cases. This hierarchy, originally proposed by Blake (2001) and extended by Caha can be rendered in simplified form as in (1):
(1) Simplified Blake/Caha hierarchy
Nominative < Accusative < Genitive < Dative < Instrumental < Comitative
The outcome of Caha’s extensive cross-linguistic survey is that syncretisms between case forms overwhelmingly involve contiguous regions of this hierarchy. I.e. ABA patterns anywhere on the hierarchy seem to be ruled out.[2]
*ABA patterns have interesting implications for the debate between RUB and PUB, and for approaches to language universality and variation more generally. On the one hand, *ABA has been used to motivate proposals that paradigmatic orderings reflect structural containment hierarchies. For example, Bobaljik (2012) argues that the structure of the superlative contains the structure of the comparative, which in turn contains that of the positive. The restrictions on possible syncretisms are then derived from the workings of spell-out, whereby (underspecified) vocabulary items expone contiguous regions or spans of these hierarchies, as we will demonstrate with examples in Section 2.2. This crucially only works as an explanation of cross-linguistically consistent patterns of syncretism if the containment hierarchies, and thus the grammatical building blocks they are constructed out of, are universal. Thus to the extent that *ABA patterns are cross-linguistically robust, they can provide crucial empirical support for the RUB view that grammatical features are universal with respect to inventory and hierarchy, as we will discuss in more detail in Section 2.
On the other hand, as we will explore in Section 3, the existence of *ABA patterns is not necessarily incompatible with a PUB-based approach to language variation. Such patterns can in principle also be derived in terms of (neo-)Gricean reasoning on the part of the language-learner. The idea is that whenever a form B stands in pragmatic competition with a form A, where B expones the interpretation β, A must expone an interpretation α that is either weaker or stronger than β. This rules out *ABA patterns whenever α and β stand in an entailment relation. Against this background, the fundamental questions this paper will try to address can be stated as follows. Do systematic interpretive contrasts across languages derive from the employment of distinct amounts of structure from universal feature hierarchies (i.e. from containment hierarchies)? Or do they stem from differing semantic specifications on simplex formatives that feed into (Neo-)Gricean pragmatic reasoning?
1.5 Nominal pro-forms as diagnostic testing ground
We will examine these questions by investigating *ABA patterns specifically in form-meaning patterns among nominal pro-forms, i.e. different types of pronouns and anaphors, cross-linguistically, based primarily on data reported by Middleton (2020). In several languages there is clear morphological evidence that anaphors are structurally complex and built on top of pronouns. E.g. the English anaphor herself transparently involves the pronominal form her in combination with a morpheme -self. Moreover, there is evidence for a cross-linguistic *ABA pattern involving synretisms between pronouns and two different classes of anaphors. The question is what consequences this should have for the analysis of a language like German, where the dedicated anaphoric form sich shows no evidence of being complex or related in any way morphologically to the pronominal sie ‘she’. Or what about the even more morphologically impoverished pattern found e.g. in Brabant Dutch varieties like Mechelen Dutch, where a single form haar (‘her(self)’) can be used both anaphorically and pronominally?
How we answer these questions speaks precisely to the debate between RUB and PUB approaches to language variation. Under RUB, the null hypothesis would be that English, German and Mechelen Dutch all have the same underlying feature inventory and hierarchy, presumably something like what is indicated by the English forms, where the anaphor is built on out of the pronoun plus something else. The morphological differences in the surface anaphor vs. pronoun paradigms across these languages would stem from language-specific Spell-Out rules for the exponence of identical features. Under PUB, on the other hand, the null hypothesis would be that distinct amounts of featural complexity for anaphors vs. pronouns are only warranted in a language like English where these correspond to distinct morphological forms. For German, a featural distinction would be warranted, but not necessarily one involving structural complexity, and for Mechelen Dutch, there would be no reason to posit an underlying distinction between anaphors and pronouns at all.
In Sections 2 and 3, we will showcase the analytic tension between RUB and PUB, respectively, with respect to the *ABA patterns for anaphors and pronouns reported by (Middleton, 2020). We will deliberately push the implications of the underlying premises in RUB and PUB to their logical extremes, so as to make the tension between them maximally clear. Most importantly, in Sections 4 and 5 we work to shift the debate between RUB and PUB from the conceptual to something more empirically grounded and develop concrete diagnostics tailored toward the anaphor vs. pronoun distinction, exploring how they can be applied in future research. This will be crucial to helping us avoid the aforementioned problem that such a debate could easily regress into an idle argument over subjective, aesthetic preference as to what constitutes cross-linguistic economy.
2 The Rich Universal Base Hypothesis (RUB)
In order to sharpen the contrast with PUB which is at the heart of this paper, we adopt a maximally strong definition of the RUB position in the following discussion, as laid out in (2).
(2) Rich Universal Base (RUB):
The basic building blocks of syntactic structure — the inventory and hierarchical ordering of grammatical features — are universal even at fine levels of detail. Structure for which there is overt morpho-syntactic evidence in one language should be assumed to be present (perhaps covertly) in all languages.
2.1 Illustrating RUB with a model
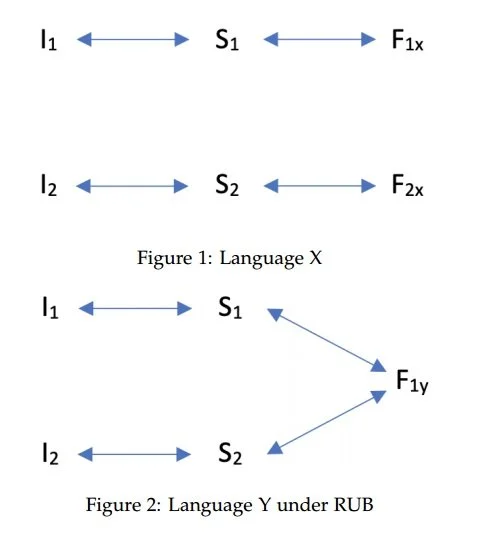
We can unpack the RUB position described in (2) by considering what it would mean to adopt it for a typical analytic scenario where we are comparing patterns in two languages X and Y. Language X shows evidence that a particular interpretive contrast — e.g. that between anaphoric and non-anaphoric reference — is tied to a contrast in grammatical building blocks. I.e. we can distinguish two interpretations I1 and I2, and these are consistently associated with two distinct forms F1x and F2x, respectively. This suggests that there are distinct structures S1 and S2 (i.e. different assemblages of grammatical building blocks) which mediate the interpretive and formal contrasts (see Figure 1). In contrast, language Y provides no morpho-syntactic evidence for such a structural contrast. The two interpretations I1 and I2 can still be distinguished semantically, but there is a single form F1y which is associated with both. What RUB amounts to is the thesis that, all other things being equal, we should nonetheless assume a structural contrast between S1 and S2 in language Y, mediating between the two interpretations and the single form (see Figure 2).
2.2 The argument from *ABA in case
As noted in Section 1.4, one important class of evidence that has been adduced for RUB comes
from *ABA patterns. To see how this works in detail, let us consider in more detail Caha (2009)’s examination of case systems introduced in Section 1.4. Recall the claim that case syncretisms are subject to a *ABA constraint along the hierarchy given in (3):
(3) Simplified Blake/Caha hierarchy
Nominative < Accusative < Genitive < Dative < Instrumental < Comitative
Caha (2009)’s proposal is that case involves articulated structures, where each case contains the next one down in the hierarchy, as in (4).
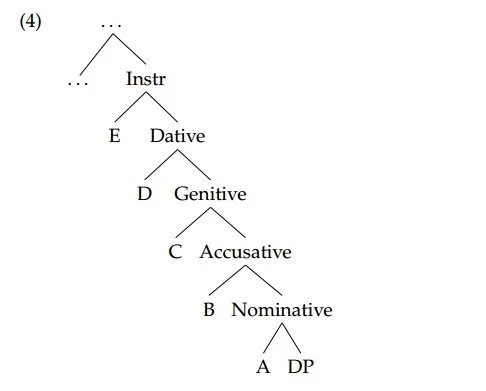
These feature structures are, crucially, universal, but languages vary in how they expone them. If exponence is constrained by some version of underspecification and the Elsewhere Principle acting on these structures, it will be impossible to derive ABA patterns outside of accidental homophony. There are a few different ways to implement this, but for concreteness we will explain it in terms of a Maximal Subset Principle. That is, the exponent with the maximal subset of the features specified in a particular morphosyntactic environment is the one chosen to spell it out, as is assumed e.g. in Distributed Morphology.[3] Assume then a language that has the set of exponents in (5):
(5)
a. [A] ⇔ X
b. [B [A]] ⇔ Y
c. [E [D [C [B [A]]]]] ⇔ W
Clearly, X will be inserted in nominative contexts, and W will be inserted in instrumentals, as these exponents are perfect matches. Y is a perfect match for accusatives, but it will also be
inserted for genitives and datives, because it has the Maximal Subset of relevant features. In both cases, W is ruled out because it is specified for features not present in the dative and genitive structures, i.e. it is not a subset at all. And X would be eligible for insertion, because it does have a subset of the features, but it is beaten out in the competition by the more highly specified Y. This yields a three-way syncretism for accusative, genitive and dative, and if we zero in on these three cases, that amounts to an AAA pattern.
How could we modify this system to try to yield an ABA pattern? We might think of adding an additional VI specified precisely to match the genitive structure. This would give us the updated inventory of VIs in (6) with the new exponent Z:
(6)
a. [A] ⇔ X
b. [B [A]] ⇔ Y
c. [C [B [A]]] ⇔ Z
d. [E [D [C [B [A]]]]] ⇔ W
However, this will not actually lead to an ABA pattern. As before, X, Y and W are perfect matches for nominative, accusative and instrumental, respectively. The new Z is a perfect match for the genitive, and will be inserted there. But what will happen in the dative? In the system laid out in (5), Y had the maximal subset of features and won out, but now it will be outcompeted by Z, which also has a subset of the relevant features, but is more highly specified and thus a better match. There is no way to add a VI for the genitive without having it spread to the dative in this way. The result is thus an ABB pattern for accusative, genitive and dative, not an ABA one. Indeed, anytime we try to set up an ABA pattern we will have this outcome.[4]
Let us consider then why such *ABA patterns as analyzed by Caha (2009) furnish evidence for RUB. The restrictions on possible syncretisms among case categories are derived crucially from the implicational containment structure that defines them. Since these restrictions are crosslinguistically consistent, that containment structure and the ordering of the features involved has to be universal. Otherwise, individual languages could fail to display *ABA at all, or they could each have their own *ABA defined on language-specific case hierarchies. In short, for any phenomenon where we observe cross-linguistically consistent *ABA patterns, we have evidence that that phenomenon involves building blocks that are universal in their details and ordering.
2.3 *ABA applied to pronouns & anaphors
Having seen the basics of applying RUB to *ABA patterns, let us turn now to the empirical domain that will serve as the focus for our comparison of RUB with PUB. Middleton (2020) presents a detailed study of form-meaning patterns involving nominal pro-forms across 80 languages. She reports that individual languages have dedicated forms distinguishing up to three distinct interpretations, as laid out in Table 2.
To a first approximation, the anaphors in Middleton’s system correspond to locally bound reflexives — elements that must be bound in a local domain. The diaphors are what are sometimes

referred to as long-distance anaphors — elements that must be bound, but not within a local domain. The pronouns, in contrast, don’t have to be bound at all and indeed must not be bound in a local domain.
Middleton shows that the association of these three interpretations with different forms crucially shows a *ABA pattern cross-linguistically. Some languages (including Icelandic and Yoruba) have three distinct forms, an ABC pattern. Others (like English and Balinese) have a single form for pronouns and diaphors, distinct from anaphors, an AAB pattern. Still others (e.g. Cantonese and Turkish) have a single form for diaphors and anaphors, which is distinct from pronouns, which is an ABB pattern. Finally, there are languages (like Kinyarwande and Samoan) that don’t make any distinctions, having the AAA pattern with a single form for all three interpretations. What does not occur in Middleton’s sample are languages with a single form for pronouns and anaphors that is distinct from that for diaphors — what would be the ABA pattern.
This is thus entirely analogous to what Caha (2009) described for case syncretism as well as to other *ABA patterns like that described by Bobaljik (2012) for suppletion in comparatives and superlatives and those described by the various papers in the Glossa Special Collection on *ABA.[5] The core of Middleton (2020)’s analysis is thus again a universal containment structure, shown in (7):
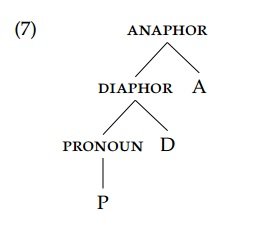
The structure of the anaphor contains that of the diaphor, which in turn contains that of the pronoun. There is a sense in which the structural complexity reflects the degree of restrictedness of the interpretation. At the most basic level of the P we find whatever interpetive information is common to all nominal pro-forms. The D head that builds diaphors adds a restriction that this element must be bound by an antecedent, and the A head adds an additional restriction that this antecedent be local. Coupled again with suitable assumptions about spell-out, this structure can be used to capture the constraints on possible syncretisms that Middleton observes.
Consider a language with the VIs in (8), again assuming that competition for exponence is regulated by a version of Maximal Subset.
(8)
a. [P] ⇔ X
b. [D [P]] ⇔ Y
Clearly, X will expone pronouns, and Y diaphors, since they are perfect matches for the relevant structural contexts. To get an ABA pattern, we would have to set things up so that X would also expone anaphors. Now, (8a) taken on its own is eligible to spell out an anaphor structure, because it is specified for a subset of the [A [D [P]]] features. However, in the language characterized by (8) it will never be able to do so, because it is in competition with (8b), which is specified for more of the relevant features and so wins out by Maximal Subset. Y thus gets inserted for anaphors and we would get here an ABB pattern.
The only way to get a surface ABA pattern would be by accidental homophony, as with the inventory of VIs in (9):
(9)
a. [P] ⇔ X
b. [D [P]] ⇔ Y
c. [A [D [P]]] ⇔ X
This is just like the system in (8), but it has an additional VI (9c) specified to exactly match the anaphor structure. Crucially, the form that it inserts happens — purely by accident — to be identical to the form supplied by (9a) for the pronoun structure. This is clearly distinct from true syncretism, because we don’t have a single exponent showing up for principled reasons in two distinct contexts, but rather two distinct exponents that happen to sound the same. Another way to put it is that this is really an ABC pattern masquerading as ABA. As a matter of principle, we can expect such things to arise occasionally by chance, but only rarely. We thus have an account for the observed *ABA pattern (with the possibility to deal with occasional counterexamples).
Middleton shows furthermore that her containment analysis of pro-forms is motivated not only by syncretism patterns, but also by transparent morphology. As noted back in Section 1.5, in some languages the make-up of the surface forms directly reflects the proposed containment structure. E.g., in many languages the anaphor is transparently built out of the pronoun plus some additional element, as in English her-self, my-self. In others, the anaphor is built on the diaphor, as in Icelandic anaphor sjálfan sig alongside diaphor sig, and in still others, like Peranakan Javanese of Semarang, there is transparent morphology corresponding to all three parts of the structure. In contrast, there does not seem to be transparent morphology suggesting any decomposition of pro-forms that would be inconsistent with the containment structure in (7). That is, we don’t find languages in which the form of the pronoun transparently includes the form of the anaphor, like a reverse version of English where, say, self is the anaphor and self-her is the pronoun.
What is crucial for the purposes of this paper is that the cross-linguistic consistency of the patterns motivates positing the structure in (7), even in languages where it isn’t transparently reflected in the morphology. That is, it supports RUB. Imagine hypothetically that languages could vary in how the different interpretations were mapped onto structure. In some languages the containment relationships would be different, e.g. with the diaphor built on the pronoun, which in turn is built on the anaphor. In others, the pronoun and anaphor interpretations would simply have no featural component in common. If this were the case, there would be no crosslinguistically consistent arrangement of the three interpretations associated with an *ABA pattern, and we would expect cases of ‘reverse’ transparent morphology as in the alternative version of English with self-her described above. Assuming that universals are at work here along the lines of RUB explains why this is not what we find.
3 The Poor Universal Base Hypothesis (PUB)
As outlined in Section 1, an alternative to RUB is PUB, the Poor Universal Base Hypothesis, which states that the building blocks of syntactic structure — the inventory and hiearchical ordering of grammatical features — should not be taken to be universal:
(10) Poor Universal Base (PUB):
Only structure for which there is overt morpho-syntactic evidence in a language should be assumed to be present in that language.
3.1 Background: PUB, UG and learnability
(10) amounts to saying that that (i) syntactic building blocks can vary considerably across languages; and (ii) to the extent that that there appear to be universal constraints on such inventories, alluding to UG should be thought of as a theoretical last resort. Only if such inventories cannot be explained otherwise can they be taken to be part of our genetic linguistic endowment.
To illustrate the differences between RUB and PUB, let’s have another look at the analytic scenario presented in Section 2.1. Suppose again that Language X shows evidence that a particular interpretive contrast (I1 vs I2) is derived from a structural contrast (S1 vs S2), where the two structures S1 and S2 receive the exponents F1 and F2, respectively. This is depicted in Figure 3 below. In contrast, Language Y provides no morpho-syntactic evidence for such a structural
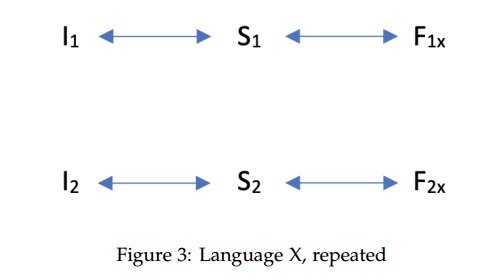
contrast. I.e., there is a single form F1 which is associated with both interpretations I1 and I2.
Now PUB says that, ceteris paribus, the interpretive contrast does not reflect a structural contrast between S1 and S2, but a single structure S1, which mediates between the two interpretations and the single form F1, as depicted in Figure 4.
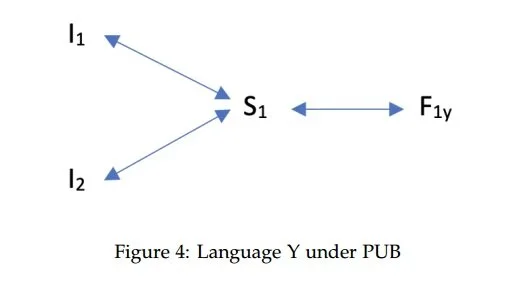
Naturally, the question arises as to whether RUB or PUB is to be preferred on theoretical and/or empirical grounds. This boils down to the bigger question as to whether any featural hierarchies that can be attested in a particular language are determined by UG or whether they are acquired during the language acquisition process. The guiding intuition behind PUB is that the default answer to this question should be the latter. The reason for this is that the attribution of grammatical knowledge to UG should be based on Poverty-of-the-Stimulus (PoS) arguments: instances of grammatical knowledge that cannot be acquired solely on the basis of the language input.
As far as language-internal featural inventories are concerned, PUB assumes an emergentist view where a language-learning child postulates the existence of certain syntactic features only if there is overt morpho-syntactic evidence for them in the language input. In other words, only those syntactic features of which there is a grammatical reflex — for instance, different parts of speech, involvement in agreement relations, triggers of movement — can be considered part of the formal feature inventory of the target language. Other potential syntactic features must be taken to be absent, irrespective of whether they are active in other languages.
The same also holds for the internal structuring of syntactic features. Again, hierarchical relations between features are learnable, provided that the child has (innate) access to the fact that syntactic structures are hierarchical in the first place (cf. Chomsky and Berwick, 2016). As such, hierarchies reflect themselves in the language input by means of inflectional orderings, (certain) word order effects, scopal relations, etc.
3.2 Universal hierarchies within PUB
As the above shows, the primary reasons to take PUB as the null hypothesis are based in language-internal grounds: only PoS-considerations form a solid conceptual reason to postulate particular instances of innate grammatical knowledge. At the same time, such a perspective faces serious empirical problems in explaining why the same hierarchical relations are attested across languages. Emergentist perspectives would predict the possibility of substantial cross-linguistic variation in this respect, contrary to what is observed. In contrast, approaches like RUB can explain such universal hierarchies in a straightforward fashion by attributing them to UG. The central question, then, when it comes to evaluating between RUB and PUB is to what extent PUB is able to account for the various universal hierarchies that have hitherto been identified.
Note then that it is not a priori excluded that such attested hierarchies could be explained on extra-grammatical grounds. In that case, no allusions to UG have to be made. From the perspective of PUB, then, apparent universal featural hierarchies only provide evidence for a universal feature structure in the absence of any extra-grammatical foundation. Put differently, only if a particular observed universal feature hierarchy cannot result from extra-grammatical mechanisms should that hierarchy be taken to be part of UG.
Now, to what extent are such extra-grammatical explanations for universal feature hierarchies available? In light of the earlier discussion, here we aim at considering what kinds of explanations might be available for *ABA patterns, like the ones observed by Caha (2009); Bobaljik (2012); McFadden (2018); Middleton (2020) and others. Again, we focus on the *ABA pattern in the domain of nominal pro-forms as observed by (Middleton, 2020). Is it possible to explain this pattern in extra-grammatical terms? Below, we formulate a particular attempt to do so.
3.3 A neo-Gricean account of *ABA for nominal pro-forms
One way to account for *ABA patterns in an extra-grammatical way is by attributing them to existing pronominal entailment relations. To see this, let us look at Middleton’s hierarchy again.:
(11) anaphor > diaphor > pronoun
This makes it possible to explain what look like syncretisms not in terms of spell-out rules targeting different parts of structures, but rather single meanings. I.e., what look like syncretisms are actually cases of single structures with an underspecified meaning, not of different structures receiving the same exponent.
To clarify this, as a starter take a look at English, which morphologically distinguishes pronouns and diaphors from anaphors, yielding an AAB pattern. There are two ways to explain the semantic differences between the following examples:
(12)
a. Oprah thinks that only Meghan loves herself.
b. Oprah thinks that only Meghan loves her.
The first is by assigning LFs in which it is encoded that herself must be bound by a local antecedent and that her may not be bound by a local antecedent (i.e., it is only non-locally bound or free). This is shown in (13a) and (13b):
(13)
a. Oprah thinks that only Meghan loves herself.
Oprah λx (x thinks that only Meghan λy (y loves y))
b. Oprah thinks that only Meghan loves her.
Oprah λx (x thinks that only Meghan λy (y loves z)), where z ̸= y
The second way is by assigning LFs like those in (14a) and (14b), where only the meaning of herself is restricted:
(14)
a. Oprah thinks that only Meghan loves herself.
Oprah λx (x thinks that only Meghan λy (y loves y))
b. Oprah thinks that only Meghan loves her.
Oprah λx (x thinks that only Meghan λy (y loves z))
The major difference between the meanings in (13a)-(13b) and (14a)-(14b) is thus that in (13b), but not in (14b), it is part of the meaning of her that it may not be bound by a local antecedent. That is, in (13b) but not in (14b) her may not refer back to Meghan.
At first sight, the second approach appears empirically weaker than the first one, as in (14b) her clearly cannot refer to Meghan. Note however that (14a)-(14b) stand in a unidirectional entailment relation: (14a) entails (14b), but not the other way round. Thus any form of (Neo)Gricean reasoning — either in terms of Maximized Presupposition or the Maxim of Quantity (depending on whether the meaning contributions of pronouns are presuppositional or assertive in nature, an issue that is orthogonal to our purposes here) — will ensure that whenever (12b) is uttered, the hearer will be able to infer that the speaker did not intend to convey the stronger meaning expressed by the (12a). Hence, the fact that in (14b) her does not refer to Meghan is still guaranteed. The ‘Principle B’-effect in (12b) results then from pragmatic competition, not from underlying differences in feature structures.
That such Principle B effects are not directly syntactically/semantically encoded, but are rather indirectly triggered as a result of pragmatic competition comes with certain advantages. First, syntactic/semantic operations are generally not known to trigger distinctness effects, which is what a syntactic version of Principle B would ultimately boil down to.[6] Second, the existence of so-called Delay-of-Principle-B effects (the phenomenon that children acquire Principle B effects much later than Principle A effects) indicates that Principle B has a different grammatical status than Principle A. Indeed, Principle B effects are only acquired at the time when children have already acquired pragmatic, (Neo-)Gricean reasoning (Chien and Wexler, 1990, et seq.), something that is fully in line with PUB. Note that this more pragmatic nature of Principle B also reflects itself in examples like (15). Whereas Principle A effects are hard-wired and cannot fail to apply, Principle B effects can thus be overridden.
(15) Talking about Suzanne, everybody likes her. Bill likes her. Peter likes her. Even Suzanne likes her.
3.4 Deriving Middleton’s observation
The above-sketched mechanism opens up the way to account for Middleton’s observation. The key here is that what appear to be syncretisms are not really instances of a single exponent corresponding to multiple structures, each with a meaning of its own, but rather cases where what underlies the single exponent really is one structure, which is associated with an underspecified meaning. For instance, in the absence of a morphological distinction between any (dia-/anaphoric) pronouns, there is simply one underlying lexical item rather than two that happen to be obscured by syncretism. Mechelen Dutch haar (’her(self)’), which can be used for all relevant meanings, is simply the spell-out of one pronominal structure that presupposes a feminine referent and has no further restrictions, thus yielding an AAA pattern.
Now let’s see what happens if there is more than one relevant exponent. Crucially, under pragmatic competition, if a stronger B stands in pragmatic competition with a weaker A, there is no way that A can be the exponent of anything stronger than B. Three meaning constructs P, Q and R — where R entails Q and Q entails P — can never be realized by means of ABA, where A is the Spellout of P, B the Spellout of Q and A again the Spellout of R, except in the case of purely accidental homophony. To illustrate this, take the following renderings of the anaphoric, diaphoric and pronominal readings:
(16) Anaphoric reading:
Oprah λx (x thinks that Meghan λy (y loves z)),
where z is y
(17) Diaphoric reading:
Oprah λx (x thinks that Meghan λy (y loves z)),
where z is x or y
(18) Pronominal reading:
Oprah λx (x thinks that Meghan λy (y loves z)),
where z is x, y or someone else
Now, consider a language with the following spell-out rules for a pronoun and its corresponding diaphor:
(19) Pronoun ⇔ X
(20) Diaphor ⇔ Y
Clearly, use of X will give rise to the pronominal reading, and use of Y to the diaphoric reading.
Based solely on (19)-(20), both Y and X may in principle also be used when an anaphoric reading is intended: they are semantically compatible with that, given that they allow z = y. However, since the reading of Y is stronger than X, the use of X for an anaphoric reading is blocked. Similarly, since the reading of Y is stronger than that of X, use of X for a diaphoric reading is blocked as well. This together creates a *ABA effect: use of pronoun X will never result in an anaphoric reading. The only way to get an ABA-pattern would be by accidental homophony as in (21), where the exponents introduced by (21a) and (21c) are clearly two different things, in spite of both being pronounced X.
(21) a. Pronoun ⇔ X
b. Diaphor ⇔ Y
c. Anaphor ⇔ X
Hence, *ABA patterns can be derived for those elements, like pronouns, diaphors and anaphors, whose underlying meaning contributions stand in entailment relations. Consequently, such *ABA patterns need not constitute evidence for a universal inventory of building blocks a là RUB. Rather, they are fully in line with the null hypothesis of PUB.
As a final remark, we note that the observation discussed in Section 2.3, that in many languages the anaphor is transparently built out of the pronoun plus some additional element (as in English her-self) can be explained under PUB as well. Crucially, the meaning of an anaphor under PUB is based on the meaning of the corresponding pronoun. The meaning of an anaphor like herself necessarily makes reference to the meaning of a pronoun like her. It is not unnatural to assume that in certain languages (though not all) these meaning structures are reflected in morpho-syntactic structures. This explains why complex anaphors are often built on simplex anaphors. In this light, it is not surprising either that cases of ‘reverse’ transparent morphology (e.g. complex pronouns built on simplex anaphors where, say, self is an anaphor and self-her is a pronoun) are not attested cross-linguistically.
Naturally, it must be emphasized that this does not make any claims about the status with respect to the universal base underlying *ABA patterns that cannot be reduced to pragma-semantic blocking. Hence, it remains to be seen whether these can also be analysed along the lines of PUB or provide evidence for RUB instead.
4 The wheel-spinning problem & how to avoid it
In this section, we discuss the importance of grounding the choice between RUB and PUB, (or some intermediate variant that combines insights from both), by means of independent empirical diagnostics. We focus in particular on what such empirical grounding might look like for the specific phenomenon that has formed the bulk of the empirical background for the discussion in this paper, namely morphological paradigms of nominal pro-forms cross-linguistically.
As should hopefully be clear, RUB and PUB are both ultimately Minimalist-compatible in the sense that both are guided by the heuristic of the SMT — that the optimal solution to language variation is the one that posits the simplest possible grammatical machinery that is capable of accounting for the empirical landscape of language universals and variation. Where they differ is in where the emphasis is placed in the notion of simplicity. Per RUB, positing the same detailed syntactic structure for all languages allows for a simpler account of cross-linguistic universals. This is prioritized even if it comes at the expense of a richer UG and the frequent use of more complex abstract structures for the analysis of an individual language than that language might itself provide direct evidence for. The guiding principle of PUB, in contrast, is that positing language-specific structural inventories allows for a simpler UG and transparent mappings between structure and form, on the one hand, and between structure and meaning, on the other in individual languages. This is seen as preferable, even if it comes at the cost of positing significant variation in syntactic structures across languages, thereby necessitating an independent account of cross-linguistic universals.
The debate between the two approaches thus ultimately reduces to one over which type of simplification should be prioritized. In the absence of an independently motivated metric of parsimony, there is no objective way to resolve this tension, and the choice between the two regresses into an idle, aesthetic exercise in speculation and pontification. How do we resolve this wheel-spinning problem? Ultimately, the only scientifically valid solution is one that is guided by questions that can be settled empirically rather than aesthetically. Of course, it is not a trivial matter to sharpen competing high-level theoretical approaches sufficiently to derive unambiguously distinct empirical predictions, or to identify actual datasets with the requisite properties to test those predictions. But this is ultimately the task that faces us.
In this section, we will lay some of the groundwork for this undertaking by developing empirical diagnostics to tease apart the RUB and PUB approaches, specifically as concerns nominal pro-forms. Anaphors and pronouns have been observed to differ both syntactically and semantically in various ways across languages. We will look at two such differences here and discuss how they can help adjudicate the choice between RUB and PUB. It is important to bear in mind that these diagnostics, even if they are conclusive in favor of one approach or the other for nominal pro-forms, do not necessarily have any bearing on how variation for a distinct linguistic phenomenon — like syncretism patterns for case or suppletion of comparatives and superlatives — should be handled.
4.1 A syntactic difference: the Anaphor Agreement Effect
One fundamental distinction between anaphors and pronouns that has been discussed in the literature has to do with the so-called Anaphor Agreement Effect (AAE). This is the observation, originally made in Rizzi (1990) and discussed at length in (Woolford, 1999; Sundaresan, 2016; Preminger, 2019; Murugesan, 2019; Raynaud, 2020, a.o.) that an anaphor cannot trigger co-varying ϕ-agreement. Pronouns, on the other hand, are capable of doing so. Rizzi’s original observation was motivated by minimal pairs like the one below, from Italian (Rizzi, 1990, 3):
(22) A loro interess-ano solo i ragazzi.
to them interest-3PL only the boys.NOM
‘Theyi are interested only in the boysi.’
(23) *A loro interess-ano solo se-stessi.
to them interest-3PL only them-selves.NOM
‘Theyi are interested only in themselvesi.’ (Intended)
ϕ-agreement in Italian is typically triggered by a nominative argument. In (22), the nominative object ‘the boys’ successfully triggers 3rd-person plural agreement on the verb. But if we replace this object with a plural nominative anaphor, as in (23), the sentence becomes ungrammatical. When the anaphor appears in the genitive case, as in (24) (Rizzi, 1990, 33), ungrammaticality is obviated and the clausemate verb surfaces with default 3rd-person singular agreement, instead:
(24) A loro import-a solo di se-stessi.
to them matters-3SG only of them-selves
‘Theyi only matter to themselvesi.’
Taken together, these patterns show that ϕ-covarying agreement is disallowed just in case the agreement controller is anaphoric, leading Rizzi to conclude that “[T]here is a fundamental incompatibility between the property of being an anaphor and the property of being construed with agreement” (Rizzi, 1990, 28). Subsequent analyses (Woolford, 1999; Haegeman, 2004; Tucker, 2011) have verified the robustness of the AAE across languages with an array of agreement and anaphor patterns. These have also shown that languages employ a range of parametrized strategies in order to avoid a violation of the AAE, for example, detransitivizing the verb, agreement-switch, default agreement or oblique case-marking the anaphor. Regardless of the specifics of these patterns, which are not our main concern here, the existence of a restriction like the AAE can be derived under the assumption that anaphors and pronouns differ featurally. These featural differences can in principle be mapped onto flat or hierarchically contained structures, and versions of both have been proposed in the literature.
Under the first approach, the distinction between anaphors and pronouns involves “flat” featural structures, i.e. different specifications in set-based feature structures, which have no bearing onthe hierarchical structure of these elements (Sundaresan, 2016; Murugesan, 2019; Raynaud, 2020). For instance, Murugesan proposes that anaphors have unvalued but interpretable ϕ-features. The syntactic correlate of anaphora is the valuation of these ϕ-features on the anaphor by a local nominal with valued ϕ-features, which is then understood to be its binder. Since the anaphor constitutes a ϕ-probe in its own right, it cannot value the ϕ-features on a ϕ-probe involved in more conventional agreement like T or v, unless the anaphor has itself already been valued by its binder by the relevant point in the derivation. Murugesan convincingly argues that such a latter state-of-affairs requires a cross-linguistically quite unlikely combination of factors. In most relevant structures in most languages, the anaphor is merged first, in object position while its intended binder is merged in subject position in Spec, vP. The ϕ-probe responsible for object agreement is merged in an intermediate position between the anaphor and its binder, e.g. v. As such, assuming probing happens as soon as possible, the anaphor has no chance to be valued by its binder at the point v probes downward for ϕ-values, because its binder will not yet have been merged in the structure. The AAE is the result of the anaphor’s failure to satisfy the needs of the v probe. The true test of the validity of Murugesan’s proposal lies in his demonstration that the few cases of apparent AAE-obviation, observed in languages like Standard Gujarati or Archi, independently involve: (i) structural orderings where the ϕ-binder is merged before the ϕ-probe responsible for agreement; and (ii) the ϕ-binder, despite being minimally closer to the downward probing functional head, is invisible to it. The anaphor is thus itself fully ϕ-valued by the time the agreement probe seeks to be valued by it, and can successfully value this probe: an obviation of the AAE, far from being unexpected, is then precisely what is predicted by such a state-of-affairs.
The second approach builds on the containment hierarchy independently motivated in Middleton (2020) to explain *ABA patterns in nominal pro-forms, as discussed in Section 2.3 above. Preminger (2019) argues that the hierarchical structure of the anaphor, which monotonically contains that of the diaphor and the pronoun, also makes it invisible as a goal for ϕ-agreement. Specifically, he argues that the outer anaphor shell functions like a barrier, trapping the ϕ-features of the pronoun under it. An anaphor is thus much like an oblique case-marked nominal, which has been argued to be analogously opaque to ϕ-probing in many languages by virtue of the K(ase) or PP shell that underlies the case-marking, which traps the ϕ-features of the nominal under it (see e.g. Rezac, 2008; McFadden, 2024). This again has the result that the anaphor cannot value the ϕ-features of a ϕ-probing head like T or v, resulting in the AAE. To explain the absence of AAE-effects in languages like Standard Gujarati, Preminger must say that the anaphoric shell exceptionally allows the percolation of ϕ-features to the root AnaphP node, which circumvents the barrierhood of that structural level.
We will not dwell here on the pros and cons of one of these approaches to the AAE vs. the other. Rather, we will point out that both depend on positing featural differences in the syntax of anaphors vs. pronouns, independent of the morphology of the anaphors and pronouns themselves. We will be able to use this to work out empirical predictions that can be used to test the RUB and PUB hypotheses.
4.2 A semantic difference: strict vs. sloppy readings under ellipsis
Anaphors and pronouns also differ in their interpretive behaviors, beyond just the basic facts of coreference. Bound variable pro-forms have been observed to yield obligatorily sloppy identity readings when c-commanded by definite DPs such as R-expressions (Reinhart, 1983). In contrast, regular pronouns may have both bound-variable sloppy readings and strict readings under definite DPs, due to their ability to refer discourse-pragmatically. This is illustrated below for constructions involving obligatorily controlled pro (which is an obligatorily bound variable) vs. a regular pronoun:
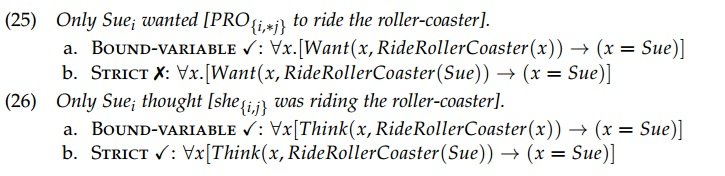
The different readings can be highlighted by clarifying what alternatives only is ruling out in each case. For (25), the implication is that Nobody else wanted to ride the roller-coaster (sloppy), not that Nobody else wanted Sue to ride the roller-coaster (strict). In contrast, for (26), the implication can be either that Nobody elsei thought shei was riding the roller-coaster (sloppy), or that Nobody elsei thought that Suej was riding the roller-coaster (strict). Similarly, a string containing an elided bound variable can only yield sloppy readings, while an analogous string containing a free one can yield strict or sloppy readings. An anaphor is conventionally understood to be an obligatorily-bound variable, with further internal sub-classifications having to do with whether this is also reflected in its syntactic structure or not (see e.g. Sundaresan, 2020, for discussion). A pronoun, in contrast, is an optionally bound one, as we have just seen. This means that an anaphor should yield only sloppy readings under ellipsis, while a pronoun should be able to yield strict or sloppy readings under ellipsis.[7]
4.3 Implications for the choice between RUB and PUB
According to RUB, there is a series of distinct syntactic structures for nominal pro-forms that is universal across languages, independent of the inventory and details of surface morphological realizations made available by each individual language. As such, regardless of what syncretism patterns are observed in their morphological forms (AAA, AAB, ABB or ABC), elements with particular interpretations should show characteristic syntactic and semantic behaviors. Concretely, under RUB, even a language that does not distinguish anaphors and pronouns in terms of their overt forms should nonetheless distinguish them featurally. Thus, whether such distinctons are implemented in terms of flat or hierarchical feature structures, such a language should still obey the AAE: there should be anaphors which are unable to trigger ϕ-covarying agreement alongside pronouns that are able to do so, even if they are pronounced the same. Similarly, the anaphor should yield only sloppy readings under ellipsis while the pronoun should be able to yield strict or sloppy readings under ellipsis.
PUB on the other hand explicitly favors a transparent mapping between syntactic structure, morphology and semantics. As such, a language with an AAA pattern (like Mechelen Dutch) should have a single, undifferentiated feature-structure, with an underspecified semantics which which can be used anaphorically or pronominally depending on the intended reading, and conditioned by pragmatic well-formedness principles of language use. Under such a view, we should find no syntactic or semantic differences between the anaphoric and pronominal uses of this undifferentiated element. Concretely, this predicts that there should be no syntactic differences relating to the AAE associated with different readings of the unified pro-form, nor should there be asymmetries in the availability of strict and sloppy readings under ellipsis.
RUB and PUB thus make distinct empirical predictions with respect to these diagnostics for languages that do not morphologically distinguish anaphors from pronouns. In the next section, we will take a first step toward putting these predictions to the test. It should be noted that what we report here is necessarily preliminary. This is because, while the distinct predictions of the two approaches are reasonably clear, actually testing them is far from trivial. For one thing, the diagnostics require a number of properties to align in the right way, which severely restricts the set of languages in which the tests can be carried out. For another, even once appropriate languages have been found, constructing paradigms to properly run the tests while avoiding various confounding facts can be quite difficult, requiring deep familiarity with the structural properties and quirks of the particular language. Finally, these are complex patterns being tested, with multiple moving parts. This means that the analysis of results is not always straightforward, with individual patterns often susceptible to multiple interpretations. This is why what we do below is necessarily a first step. We describe the relevant tests and how things are predicted to turn out by RUB and PUB, note some specific languages with the requisite properties for the tests to be run, and give a preliminary view of the data. We leave it to future work to carry out the tests in full detail and analyze their results for specific languages.
5 Testing the predictions
5.1 Testing the AAE
Testing the AAE involves selecting languages from the Middleton survey (or finding others from outside the survey) that satisfy the following input conditions: (i) the language shows an AAA syncretism pattern for three categories of nominal pro-form: (ii) the language allows ϕ-agreement at least under certain circumstances with argument positions where forms with anaphoric interpretation can appear, typically object positions.
Of the 80 languages surveyed in Middleton (2020), only seven are reported to have AAA patterns. These are: Bislama (English-lexifier Creole), Fijian (Austronesian), Georgian (Kartvelian), Kinyarwanda (Niger-Congo), Madurese (Austronesian), Samoan (Austronesian), and Tongan (Austronesian). To this, we can add Brabant Dutch dialects like Mechelen Dutch and also Old English (see van Gelderen, 2000, for extensive discussion of the latter, with its historical developments). However, while these languages all satisfy our first input condition, most do not fulfill our second, either because they lack ϕ-agreement entirely or because they only have subject agreement, whereas the anaphor is typically in object position, bound by the subject.[8]8 We are left with two languages which, at least on the surface, seem to satisfy both input conditions: Georgian and Kinyarwanda. We look at these in turn. As we will see, Georgian has to be excluded for independent reasons, but Kinyarwanda might ultimately allow the test to be run.
5.1.1 The AAE in Georgian
Closer inspection reveals that Georgian actually does have dedicated anaphoric and diaphoric
pronouns after all. Middleton provides the examples in (27)-(28), suggesting that the expression igi may refer back to Kanga, Piglet or another person.

However, our consultant tells us that for them only the diaphoric reading is available with igi. For the anaphoric and pronominal readings, a true anaphoric pronoun tavisi tavi, literally ‘his head’, and a regular pronoun is (’him’) must be used, respectively. This means that the language does not show an AAA pattern after all. So even though Georgian is a language with object agreement, it cannot help us in evaluating between RUB and PUB — both approaches would posit distinct feature structures to go along with the three distinct surface forms, and so they make the same predictions for the language with respect to the AAE.
5.1.2 The AAE in Kinyarwanda
Given these considerations, Kinyarwanda emerges as our lone remaining candidate for testing
the applicability of the AAE with syncretic forms. It is, as desired, an AAA language that allows object agreement and also has structures where the syncretic anaphor/pronominal form shows up in object position. This is illustrated below (Middleton, 2020, Ex. 232, p. 119):

The question we must ask is the following: does the syncretic anaphor/pronominal form, which gets the anaphoric interpretation in (29), show evidence for the AAE? And is the relevant effect then absent in (30), where the same form receives a pronominal interpretation? If the answer to these questions is in the affirmative, we have a potentially strong piece of evidence in favor of RUB, since this speaks to the idea that the anaphor and pronoun are featurally distinct despite being morphologically indistinguishable.
Intriguingly, such evidence does seem to be present, at least on a first survey of these examples. The local anaphoric use of we wenyiwe in (29) does not trigger object marking on the verb. In contrast, the diaphoric and pronoun uses of the same form do trigger co-varying object marking (the verbal prefix -mu) in (30). These effects would follow automatically from the AAE under a RUB analysis of the facts. The reasoning would be that the anaphoric use of we wenyiwe in (29) corresponds to a dedicated anaphoric feature structure (whethere flat or hierarchical) in the syntax, which renders it unable to value the object ϕ-probe; but the pronominal use in (30) corresponds to a distinct pronoun feature structure which can value the object ϕ-probe. In other words, this can be taken as initial support for a RUB-based approach to the anaphor vs. pronoun distinction, since we have evidence here from agreement-triggering possibilites for distinct feature structures underlying the surface-identical forms for the two interpretations.
At the same time, we should not be too hasty in reaching this conclusion. As pointed out to us by Neil Banerjee (p.c.), reporting from (Kimenyi, 1980), the verbal prefix -i- in (29) is a noun class-invariant reflexive marker that takes the place of object agreement. For these patterns to constitute legitimate support for RUB, we still need to show that the object marking -mu in (30) does indeed instantiate a regular object agreement marker, whereas the reflexive marker -i- really is a kind of agreement marker that is specific to anaphoric objects. Only then do we have a genuine AAE pattern in Kinyarwanda. The alternative is that the object-marking distinction between (29) vs. (30) has to do with independent differences in the structural environment where the pronoun/anaphor is merged that don’t actually involve proper agreement. For example, the reflexive marker in (29) could have to do with the presence of a reflexive voice/v head, rather than any Agree dependency with the anaphoric object, and the presence of the object marker in (30) could instantiate clitic-doubling rather than agreement. In that case, these surface patterns would still be compatible with a PUB-minded approach. We thus see why running these tests is not a trivial matter and, in particular, requires deep analytic expertise with the languages involved. Still, to the extent that such alternatives are fully empirically testable, future careful investigation of Kinyarwanda could be probative for the RUB/PUB-debate, at least for the analysis of nominal pro-forms.
5.2 Testing the strict vs. sloppy distinction
The other empirical diagnostic relates to the behavior of pronouns vs. anaphors with respect to the availability of strict and sloppy readings under ellipsis. Here, we need languages which satisfy just one input condition: they should have an AAA syncretism paradigm for anaphor, diaphor and pronoun interpretations.

For languages with an AAA pattern, RUB and PUB make different predictions for such ellipsis constructions. Under RUB, the two types of examples, despite being homophonous, would still involve two distinct structures corresponding to (31) and (32), containing an underlying anaphor and an underlying pronoun, respectively. This means that if the first conjunct has an anaphoric interpretation, the second conjunct should yield one as well, and thus only allow for a sloppy reading. A non-anaphoric interpretation in the first conjunct, on the other hand, should yield non-anaphoric behavior in the second conjunct as well, in particular allowing a strict reading and also triggering a Principle B effect.
By contrast, under PUB these languages only have one underlying element, with an underspecified semantics, that can be used with either anaphoric or pronominal reference. This means that the (non)-anaphoric interpretation of the first conjunct should not force (non)-anaphoric interpretation of the second one. In other words, under PUB, we do not predict a contrast whereby there is an obligatory sloppy reading in the second conjunct only when the first conjunct has an anaphoric interpretation.
Again, a proper test of these predictions will require an extensive and systematic investigation, based on language-specific expertise and taking measures to control for potential interfering factors (like the effects of the parallelism constraint on ellipsis sites, which can be expected to rule out certain readings independent of whether one adopts a PUB or RUB approach). Nonetheless, to illustrate the test we have consulted with a Brabant Dutch informant, who speaks a dialect — Heusden Dutch — with an AAA pattern similar to that in Mechelen Dutch. They tell us that, for them, the example in (33), where the pro-form in the first conjunct is interpreted as locally bound, does not come with an obligatory sloppy reading in the ellipsis site, although the sloppy reading is the preferred one.

The facts in this case thus preliminarily point in the direction of PUB over RUB, since the latter would lead us to expect the sloppy reading to be required, not just preferred. Obviously, as in the Kinyarwanda case, more research needs to be carried out before any firm conclusion can be drawn for the analysis of nominal pro-forms, though. While this would have been the case regardless of how the preliminary results of the two tests came out, it is made especially clear by the fact that they seem to point in opposite directions.
6 Conclusion
It is a fundamental question for linguistic theory to explain which aspects of natural language are universal and which ones are language-specific. Such aspects concern, among other things, the inventory of grammatical building blocks, the ways in which these building blocks can be combined, and how they are organized and ordered relative to each other. A number of different perspectives have been formulated in the literature on the balance of universality and cross-linguistic variation on these points. In this paper, we have sought ways to sharpen these questions of language universality vs. language variance empirically, via the lens of cross-linguistic patterns of form-meaning pairings involving nominal pro-forms. In particular, we have examined the implications of morphological patterns of syncretisms across classes of anaphor, diaphors and pronouns for two Minimalist-compatible, but nevertheless opposing, views of language variation which we have labeled the Rich Universal Base (RUB) and Poor Universal Base (PUB) hypotheses.
As (Middleton, 2020) has shown, a *ABA effect can be identified within the domain of nominal pro-froms. That is, there is no language where a pronoun and an anaphor have the same morphophonological form, but where a diaphor has a distinct one. *ABA patterns like this can shed light on the debate between RUB and PUB and indeed have played an important role especially in motivating recent RUB proposals. Under RUB, the null hypothesis would be that all languages have the same underlying feature-inventory and/or functional-hierarchy for anaphors, diaphors and pronouns, irrespective of whether these receive different forms or not. Under PUB, the null hypothesis would be that distinct featural inventories and hierarchies for the anaphor vs. pronoun distinction are only warranted in languages where these correspond to distinct morphological forms. The question then arises whether the observed *ABA pattern provides crucial empirical support for the RUB view that grammatical features are universal with respect to inventory and hierarchy, as is often assumed, or whether the existence of this *ABA pattern is also compatible with a PUB-based approach to language variation.
Against this background, we shown here that (Middleton, 2020)’s observed *ABA pattern can indeed be captured under a PUB-based approach as well, being derived in terms of (neo)Gricean reasoning applying to elements in pragmatic competition. However, the fact that both RUB and PUB approaches could in principle cover the basic *ABA facts does not mean that the choice between the two cannot be evaluated empirically. Rather, as we have shown, the two make distinct predictions about the behavior of surface-ambiguous nominal pro-forms with respect to the so-called Anaphor Agreement Effect (AAE) and strict vs. sloppy interpretations under ellipsis. Although our preliminary investigations here have not led to a particular outcome in the debate, we have laid the groundwork for seeking that outcome in future research by spelling out what exactly the different RUB- and PUB-based predictions are, and how they can put to test empirically.
As mentioned at the outset, we have deliberately chosen to describe the strongest possible versions of RUB and PUB in the preceding sections so as to more clearly illustrate the analytic tension between them. But it is important to bear in mind that these are ultimately logical poles which stand at opposite ends of a continuum of possible ways to capture patterns of language variation. The perhaps more realistic question is not about a binary choice between RUB and PUB. Rather, we should ask where along the continuum we find the optimal balance between detailed empirical coverage of cross-linguistic variation and language universals without an overburdened UG. Below, we describe a few concrete scenarios that showcase what such an optional solution to language variation, intermediate between RUB and PUB, might look like.
Consider first two specific proposals in the literature for approaches to variation that are intermediate between RUB and PUB, from Ramchand and Svenonius (2013) and (Wiltschko, 2014). The core idea of Ramchand and Svenonius (2013) is described in the following excerpt: “We adopt (as working hypothesis) the Minimalist conjecture that a fine-grained hierarchy of functional heads cannot be part of UG; that is, it cannot be innate and specific to language. We are persuaded that Cartographic work shows that there are fine-grained hierarchies of functional heads in each language, and that they are similar to each other . . . ” (p. 3). To this end, Ramchand & Svenonius propose a universal tripartition of the clause into a V-domain, a T-domain and a C-domain, but they ground this in terms of sortal domains based on conceptual primitives, themselves ordered as Proposition > Situation > Event due to how their meanings build on each other. Further articulation within these domains can be language-specific in its level of granularity at different points and its details, allowing for the real cross-linguistic variation that is found. However, since all of that articulation must be consistent with the basic semantics of the sortal domains, much of what is found even at the level of detail will be consistent across languages.
The Universal Spine Hypothesis developed in Wiltschko (2014) is similar in spirit but varies in the details. Wiltschko proposes that (i) “language-specific categories (c) are constructed from a small set of universal categories κ and language-specific UoLs [Units of Language]; [c = κ + UoL]. (ii) The set of universal categories κ is hierarchically organized where each layer of κ is defined by a unique function” (p. 24). In other words, just as in Ramchand & Svenonius’ model, we start with a sparse set of universal categories which can then serve as a universal base to construct language-specific categories with. Such an intermediate position has the advantage of being able to balance universality, in the form of κ, with language-specificity, in the form of c.
A different class of intermediate solution (which could, incidentally, be comfortably combined with approaches like the two just discussed) involves proposing that the kind of approach to language variation one adopts should be relativized to the empirical phenomenon in question. This is equivalent to claiming that the choice between RUB and PUB is not an absolute one but must be made on a case-by-case basis. Specifically, RUB might well be more appropriate for phenomena whose empirical footprint has a primarily morpho-syntactic characterization. For instance, it is difficult to imagine how a neo-Gricean PUB-style account based on the interpretations associated with competing morphological forms could account for the intricacies of the *ABA patterns in case syncretism, given that there aren’t clear semantic entailment relationships between the cases that could serve as the basis for pragma-semantic blocking, especially the more structural cases. As we have already seen in Section 2.2, a RUB-based account like that in Caha (2009) can readily deal with such patterns in terms of syntactic containment hierarchies. Conversely, a PUB-oriented approach might be better suited for contrasts which are heavily supported by interpretive evidence, with clear (semantico-pragmatic) entailment relations holding between the meanings underlying forms A, B and C. The distinction between pronouns, diaphors and anaphors is largely defined in terms of interpretation, and this is what makes it reasonably straightforward to articulate a version of PUB to model the relevant patterns.
References
Baunaz, Lena, Liliane Haegeman, Karen de Clercq, and Eric Lander, ed. 2018. Exploring nanosyntax. Oxford: Oxford University Press.
Blake, Barry. 2001. Case. Cambridge University Press, second edition.
Bobaljik, Jonathan David. 2012. Universals in comparative morphology: Suppletion, superlatives, and the structure of words. Cambridge, Mass.: MIT Press.
Caha, Pavel. 2009. The nanosyntax of case. Doctoral Dissertation, University of Tromsø.
Caha, Pavel, and Guido vanden Wyngaerd. 2017. *ABA. Special collection in Glossa: a journal of general linguistics.
Chien, Yu-Chin, and Ken Wexler. 1990. Childrens knowledge of locality conditions in binding as evidence for the modularity of syntax and pragmatics. Language Acquisition 32:225–295.
Chomsky, Noam. 1965. Aspects of the theory of syntax. Cambridge, Mass.: MIT Press.
Chomsky, Noam. 2000. Minimalist inquiries: the framework. In Step by step: Essays on minimalism in honor of Howard Lasnik, ed. Roger Martin, David Michaels, and Juan Uriagereka. Cambridge, Mass.: MIT Press.
Chomsky, Noam. 2001. Derivation by phase. In Ken Hale: A life in language, ed. Michael Kenstowicz. Cambridge, Mass.: MIT Press.
Chomsky, Noam, and Robert Berwick. 2016. Why only us?. Cambridge, MA: MIT Press.
Cinque, Guglielmo. 1999. Adverbs and functional heads: a cross-linguistic perspective. Oxford University Press.
Evans, Nicholas, and Steven Levison. 2009. The myth of language universals: Language diversity and its importance for cognitive science. Behavioral and Brain Sciences 32:429–49.
van Gelderen, Elly. 2000. A history of English reflexive pronouns: Person, self, and interpretability. Amsterdam: John Benjamins.
Haegeman, Liliane. 2004. A DP-internal Anaphor Agreement Effect. Linguistic Inquiry 35:704–712.
Haspelmath, Martin. 2007. Pre-established categories don’t exist: consequences for language description and typology. Linguistic Typology 11:119–132.
Kimenyi, Alexandre. 1980. A relational grammar of kinyarwanda, volume 91 of University of California Publications in Linguistics. Berkeley: University of California Press.
Martinović, Martina. 2015. Feature geometry and head-splitting: evidence from the Wolof clausal periphery. Doctoral Dissertation, University of Chicago, Chicago, IL.
McFadden, Thomas. 2018. *ABA in stem-allomorphy and the emptiness of the nominative. Glossa: a journal of general linguistics 3:8.
McFadden, Thomas. 2024. A synthesis for the structural/inherent case distinction and its comparative and diachronic consequences. In The place of case in grammar, ed. Elena Anagnostopoulou,
Dionysios Mertyris, and Christina Sevdali, 175–214. Oxford: Oxford University Press.
Middleton, Hannah Jane. 2020. *ABA syncretism patterns in pronominal morphology. Doctoral Dissertation, University College London, London, UK.
Murugesan, Gurujegan. 2019. Predicting the Anaphor Agreement Effect and its violations. Doctoral Dissertation, University of Leipzig.
Pearson, Hazel. 2013. The sense of self: Topics in the semantics of de se expressions. Doctoral Dissertation, Harvard University, Cambridge.
Preminger, Omer. 2019. The Anaphor Agreement Effect: further evidence against binding-as-agreement. University of Maryland, https://ling.auf.net/lingbuzz/004401.
Pylkkänen, Liina. 2002. Introducing arguments. Doctoral Dissertation, MIT, Cambridge, Mass. Ramchand, Gillian, and Peter Svenonius. 2013. Deriving the functional hierarchy. Presented at GLOW 36.
Raynaud, Louise. 2020. The features of binding and person licensing. Doctoral Dissertation, University of Göttingen.
Reinhart, Tanya. 1983. Anaphora and semantic interpretation. Croon Helm linguistics series: Anaphora. Croon Helm.
Rezac, Milan. 2008. Phi-agree and theta-related case. In Phi theory: Phi-features across modules and interfaces, ed. Daniel Harbour et al., 83–129. Oxford: Oxford University Press.
Richards, Norvin. 2010. Uttering trees. Cambridge, Mass.: MIT Press.
Rizzi, Luigi. 1990. Relativized minimality. Cambridge, Mass.: MIT Press.
Rizzi, Luigi. 1997. The fine structure of the left periphery. In Elements of grammar, ed. Liliane Haegeman, 281–337. Dordrecht: Kluwer Academic Publishers.
Ross, John Robert. 1970. On declarative sentences. In Readings in English transformational grammar, ed. Roderick Jacobs and Peter Rosenbaum, 222–277. Waltham, Mass.: Ginn.
Starke, Michal. 2009. Nanosyntax: a short primer to a new approach to language. Nordlyd: Special issue on Nanosyntax 36:1–6. Edited by Peter Svenonius, Gillian Ramchand, Michal Starke, and Knut Tarald Taraldsen.
Sundaresan, Sandhya. 2016. Anaphora vs. agreement: a new kind of Anaphor Agreement Effect in Tamil. In The impact of pronominal form on interpretation, ed. Patrick Grosz and Pritty Patel-Grosz. de Gruyter, Mouton.
Sundaresan, Sandhya. 2020. Distinct featural classes of anaphor in an enriched person system. In Agree to Agree: Agreement in the Minimalist Programme, ed. Katharina Hartmann, Johannes Mursell, and Peter W. Smith, Open Generative Syntax, 425–461. Language Science Press.
Sundaresan, Sandhya. 2024. Deriving assimilation & dissimilation in syntax: ϕ vs. case. Ms., Stony Brook University, https://ling.auf.net/lingbuzz/007795.
Tucker, Matthew A. 2011. Even more on the anaphor agreement effect: when binding does not agree. Manuscript written at UCSC.
Wiltschko, Martina. 2014. The universal structure of functional categories: Towards a formal typology. Cambridge, UK: CUP.
Woolford, Ellen. 1999. More on the anaphor agreement effect. Linguistic Inquiry 30:257–287.
***
[1] We are simplifying a bit here, as Modern Greek additionally distinguishes a vocative case in certain declension classes, but it does not present any difficulties for the analysis.
[2] Caha (2009) also argues that the hierarchy constrains morphological case inventories cross-linguistically. If a language realizes a given category as morphological case (as opposed to, say, marking it with an adposition), it will also realize all of the categories lower on the hierarchy in (1) as morphological case. This is in essence another *ABA pattern, where A is understood as ‘realized as morphological case’ and B is understood as ‘realized as adposition’.
[3] We’re doing it this way to simplify the transition to the our discussion of Middleton (2020)’s proposal for pronouns and anaphors, which works along similar lines. Caha (2009), operating within Nanosyntax, actually uses a Minimal Superset Principle. There are real and important differences between the two approaches, but they are orthogonal to the concerns of this paper, so we can safely set them aside.
[4] Caha (2009) argues that the effects having to do with case inventories can be derived from this structure as well, as long as it is coupled with suitable assumptions about the workings of morphosyntax. Essentially, the operation that ensures that a particular structure will be realized as affixal morphology has to operate successive-cyclically.
[5]https://www.glossa-journal.org/collections/special/aba/
[6] That is, there are familiar grammatical operations like reduplication, clitic-doubling and agreement that create copies or make two elements in a grammatical dependency more similar to each other. It is harder to come up with ones that make elements in a grammatical dependency less similar (though see Richards, 2010 for discussion of potential examples under the rubric of Distinctness as well as Sundaresan, 2024 for arguments that dissimilatory effects are in fact found in the syntax, but they are far less common than assimilatory ones for principled reasons.
[7] A different diagnostic which appeals to the same distinction has to do with the availability of de se vs. de re readings in the scope of an attitude. An anaphor should yield only de se readings under an attitude while a pronoun can yield de re or de se readings. However, we do not pursue this diagnostic further here. For one thing, such a distinction is notoriously difficult to test. For another, there is independent reason to doubt its cross-linguistic robustness: e.g. Pearson (2013) argues that logophoric pronouns in Ewe can be interpreted de re under attitudes in certain contexts.
[8] Old English might also fulfill the second criterion in constructions with quirky dative subjects, but it would be a significant challenge to get at the necessary data to run the tests from a dead language, even one with as large a corpus of surviving texts and tools for studying it as Old English has.